

Low-Rank Adaptation of LLaMA 3 for Nepali and Hindi
PEFT Techniques and Findings from Fine-tuning LLaMA 3 with Low-Rank Adaptation for Nepali and Hindi

The space of open-source and open-weights Large Language Models (LLMs) is growing and it is great news for practitioners, researchers and consumers of these advanced AI models. Now, individuals and organizations, who otherwise have limited financial resources to cover the substantial costs associated with pre-training “can leverage” these open-source and open-weights LLMs for their specialized use cases. However, adapting these LLMs for specialized use cases remains an involved and expensive process, especially when it comes to implementing them in low-resource settings. A lot of times, these adaptations require significant computational resources and expertise, which can be challenging to obtain in resource-constrained environments. This is particularly true when dealing with low-resource languages and domains that have not been seen or have had little exposure during the pre-training process.

In the previous post, we discussed different methods used in aligning LLMs to specific tasks and desired behaviors, including Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF), both of which are expensive and challenging tasks that involves a complex process and a carefully curate high quality dataset.
Aligning LLMs - Fine-Tuning LLaMA with SFT and RHLF

Large Language Models (LLMs) like LLaMA are pretrained with large amounts of unlabeled text with self-supervised training objectives like next token prediction. Pretraining LLMs with self-supervised objectives allows the model to learn rich representation in language and across different domain from the large volume of unlabeled text that is readily ava…
In this post, we will focus on methods for fine-tuning LLMs to adapt them to specific domains and use cases in resource constraint settings. We will discuss different Parameter Efficient Fine-Tuning (PEFT) techniques. We will share our results from fine-tuning LLaMA 3 for Nepali and Hindi, two South Asian languages, one of which is a high-resource language and another is a low-resource language.
Fine-Tuning LLMs
A language model is pretrained on massive corpora of unlabelled texts, during which it learns rich representations about language and acquires general knowledge across multiple domains without relying on explicit annotations. After the initial pretraining, LLMs are fine-tuned, often using human-curated data for specialized goals and use cases. Fine-tuning is computationally cheaper than pretraining the model, but full fine-tuning of LLMs can still be computationally unachievable for a large number of individuals and institutions. As pretrained language models continue to grow in size, research into computationally efficient methods to fine-tune these LLMs is also evolving.
Parameter Efficient Fine-Tuning
During a full fine-tuning, a pretrained model is initialized with the pretrained weights and all of the model parameters and layers are trained and updated. This requires a substantial amount of curated data and computational resources as the model is trained from scratch for specific use cases. In contrast, Parameter Efficient Fine-Tuning (PEFT) methods aim to adapt LLMs by reducing the number of trainable parameters or update a small number of additional parameters or modifying only a subset of the pretrained parameters - all while maintaining the comparable performance of a full fine-tuning.
PEFT Methods
Several PEFT methods have evolved over the years, each offering a way to adapt large pretrained models without the need for full fine-tuning of the model parameters.

Some popular PEFT methods as also discussed in Parameter-Efficient Fine-Tuning Methods for Pretrained Language Models: A Critical Review and Assessment involve:
Additive fine-tuning involves adding new trainable parameters to the pretrained models while keeping the original pre-trained weights frozen. Some popular examples of additive fine-tuning include adapters, prefix tuning and prompt-based fine-tuning.
Partial or selective fine-tuning involves selecting and updating only a subset of pretrained model parameters. Layer-wise bias update, sparse fine-tuning of selected weights are some methods of partial fine-tuning of pretrained models.
Reparameterized fine-tuning methods leverage low-rank transformations of high-dimensional matrices enabling the efficient adaptation of LLMs by introducing a small number of new parameters that interact with the original model weights. Low-Rank Decomposition and LoRA are popular examples of reparameterized fine-tuning.
For this work, we will be fine-tuning a quantized LLaMA 3 8B model using a efficient reparameterized fine-tuning method called Low-Rank Adaptation (LoRA).
Low-Rank Adaptation (LoRA)
Low-Rank Adaptation, proposed in LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS, is one of the popular PEFT methods used in adapting LLMs. LoRA is based on the concept of intrinsic dimensionality and draws on the findings from two key studies: MEASURING THE INTRINSIC DIMENSION OF OBJECTIVE LANDSCAPES and INTRINSIC DIMENSIONALITY EXPLAINS THE EFFECTIVENESS OF LANGUAGE MODEL FINE-TUNING.” These studies demonstrated that over-parameterized pre-trained models possess very low intrinsic dimensions, i.e., the minimum number of parameters needed to achieve optimal performance is significantly lower than the total parameter count of the models.
“We take inspiration from Li et al. (2018a); Aghajanyan et al. (2020) which show that the learned over-parametrized models in fact reside on a low intrinsic dimension.
- LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
LoRA allows efficient finetuning of large over-parameterized models like LLMs by focusing on the low intrinsic dimensionality. It works by decomposing the weight update matrices into two low-rank matrices, which drastically reduces the number of parameters that needs to be trained during model fine-tuning. Hence, also decreasing the amount of compute required in adapting the model, while maintaining the model performance.

Full fine-tuning v/s LoRA. During full fine-tuning of LLMs, the weight changes ΔW is computed and applied directly to the pretrained weights.
In case of LoRA, the weight update matrices is decomposed into two low-rank matrices, A and B. Thus, the weight update can be generalized as:
This decomposition drastically reduces the number of parameters that need to be updated.
Let’s consider LLaMA 3 8B model for example. The model has ~8 billion parameters, i.e. n ≈ 8 × 10^9 parameters. For simplicity, we will assume we have a single weight matrix with ~8 × 10^9 parameters that needs to be updated.
During a full fine-tuning:
We would update all 8 billion parameters.
The weight change matrix, ΔW, would also be an 8 billion parameter matrix.
Both W and ΔW are 8 billion parameters.
Since, LoRA decomposes the weight change into two low-rank matrices, A and B.
Where d is the number of rows and k is the number of columns in the original matrix; and r is the rank of the decomposition, which is much smaller than the original 8 × 10^9. The weight update is approximated as: ΔW ≈ AB. The number of parameters in A and B combined (d×r + r×k) is much smaller than the original 8 × 10^9 parameters.
Say, the dimensions of the original matrix is d = 80,000 and k = 100,000, for the full fine-tuning, the number of trainable parameters is: d × k = 80,000 × 100,000 = 8,000,000,000 (8 billion).
In case of LoRA with r=16, the number of trainable parameters is: 80,000*16+16*100,000 = 2,880,000.
Thus, the number of trainable parameters is reduced drastically using LoRA, which offers memory and compute efficiency during fine-tuning. However, it's important to note that in practice, the percentage reduction would differ from our simplified example given the real models have multiple weight matrices distributed across different layers of the large models instead of just one.
In addition to reducing the number of trainable parameters, LoRA has added advantages including:
A pre-trained model can be frozen and shared across smaller LoRA modules and efficiently switched for different tasks. This reduces the storage requirement and overhead with respect to switching tasks significantly.
Since, LoRA only optimizes the low-rank decomposition matrices, the memory requirement is much lower and training is more efficient.
LoRA does not add any inference latency since the trainable matrices can be merged with the frozen pretrained weights.
LoRA finetuning can be combined with other PEFT methods like prefix tuning.
Quantized Low-Rank Adaptation (QLoRA)
Quantized Low-Rank Adaptation, introduced in QLORA: Efficient Finetuning of Quantized LLMs, is a variant of LoRA which further reduces the memory used during model fine-tuning. Pretrained model weights are stored in 32-bit precision, which consumes significant memory. While LoRA reduces the memory requirement in comparison to full fine-tuning, it does not suffice for training very large models on consumer devices. QLoRA addresses this by first quantizing a pretrained model to 4-bit precision and then training LoRA on top of this.
“QLORA reduces the average memory requirements of finetuning a 65B parameter model from >780GB of GPU memory to <48GB without degrading the runtime or predictive performance compared to a 16- bit fully finetuned baseline.
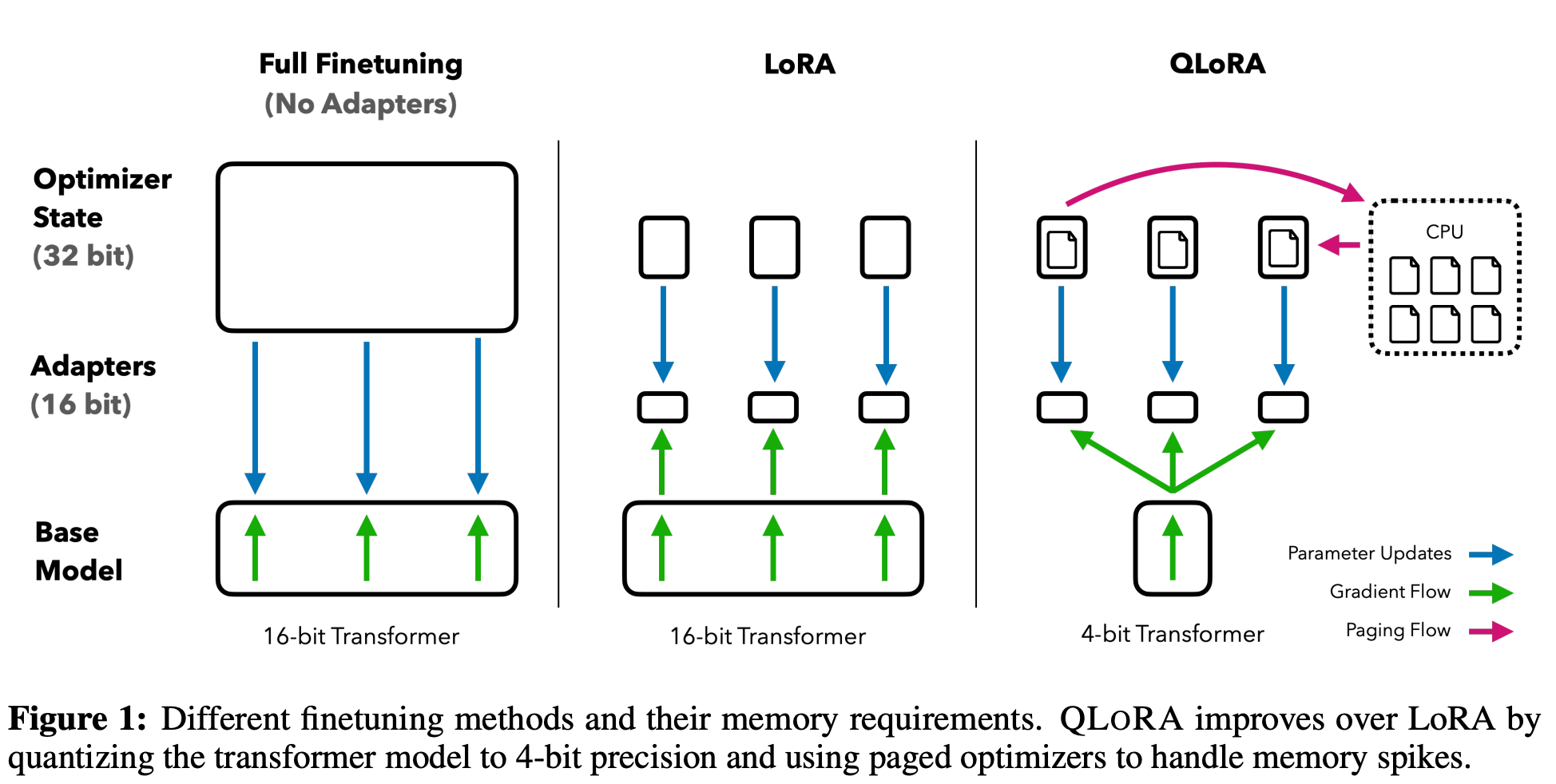
QLoRA offers reduced memory usage without sacrificing performance and it achieves this through three key techniques: 4-bit NormalFloat Quantization, Double Quantization, and Paged Optimizers.
“QLORA introduces a number of innovations to save memory without sacrificing performance: (a) 4-bit NormalFloat (NF4), a new data type that is information theoretically optimal for normally distributed weights (b) Double Quantization to reduce the average memory footprint by quantizing the quantization constants, and (c) Paged Optimizers to manage memory spikes.
More on model quantization on the upcoming series “TinyBits”, where I will explore tiny models, and discuss the latest techniques and research focused on optimizing smaller models for performance and efficiency!
In the following sections, we will present our experiments and findings from LoRA fine-tuning of the LLaMA 3 8B model for Hindi and Nepali, two South Asian languages written using Devanagari script. Our previous analysis of the LLaMA 3 tokenizer revealed improved tokenization for these languages compared to the LLaMA 2 variant. However, we also observed that the tokenization quality still lags significantly behind that of English. For more details on this tokenization analysis refer to the post below.
Exploring multilingual aspects and vocabulary of LLaMA 3 compared to LLaMA 2

Meta AI launched LLaMA 3 earlier on Thursday: LLaMA-8B and 70B models. While I can't wait to conduct a comprehensive study of the model's multilingual abilities, in this introductory blog post, I will briefly discuss how it differs from LLaMA 2. Much of the information shared here is already available as part of the model's release notes. However, this…
Experiment: QLoRA Fine-tuning LLaMA 3 8B Model
The next set of experiments is to assess the baseline capabilities of LLaMA 3 for Hindi and Nepali and evaluate the effectiveness of QLoRA fine-tuning for these languages. We have strategically chosen these two languages to explore the model's capabilities in non-Latin scripts, representing different resource scenarios:
Hindi: A high-resource language with a significant amount of digital content.
Nepali: A comparatively low-resource language with limited digital content.
We used usloth library for our experiments, because it offers a straight-forward way of fine-tuning LLMs along with enhanced speed during fine-tuning. Additionally, the availability of pre-quantized models makes unsloth an attractive choice for our experiments.
Experimental Setup
Dataset. We utilized Hindi and Nepali translations of the Alpaca Dataset, a popular instruction-tuning dataset released as a part of the Stanford Alpaca Project, which aims to build an instruction-following LLaMA model. We split this dataset into train and test sets and fine-tune the models using the train split.
QLoRA Setup. All the experiments and results in this post uses the following configuration for QLoRA finetuning:
model = FastLanguageModel.get_peft_model(
model,
r = 16,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth",
random_state = 3407,
use_rslora = False,
loftq_config = None,
)Metrics and Evaluation Criteria. We calculated rougeL and BLEURT scores with respect to the ground truth responses. In addition, we used ChatGPT as a judge to grade the responses for each of the following criteria. We manually reviewed the scores from different GPT versions and found that GPT-4-o is relatively more reliable in grading the responses, so the results that are posted/discussed below are from GPT-4-o. The responses will be graded on a 10-point scale, with 1 being the lowest and 5 being the highest score.
Relevance to instruction: How relevant is the response generated by LLaMA 3 to the instruction and input to the model.
Clarity and coherence: How clear and coherent is the response generated by LLaMA 3.
Syntax and grammar: How correct is the syntax and grammar of the generated response.
Completeness: How complete is the response.
Since in our early analysis we observed several instances of hallucinations, we also asked GPT to identify if any hallucination exists in the response.
Hallucination Type: Identify if the model response has any type of hallucination: factual inaccuracies, nonsensical responses, contradictions, repetitions or others.
Results
Overall, the baseline LLaMA 3 4-bit model showed a poor ability at generating both Nepali and Hindi, with low scores across all metrics and criterias. Surprisingly, the performance in Hindi (high-resource and one of the eight languages supported by LLaMA 3) was sometimes worse than Nepali (low-resource). This suggests that the challenges in adapting to non-English languages extend beyond resource availability.
“Llama 3 supports 8 languages — English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai, although the underlying foundation model has been trained on a broader collection of languages.
QLoRA fine-tuning for both Hindi and Nepali significantly improved performance across all metrics and criteria. Score distributions for the fine-tuned model (orange) shifted towards higher values for all the four criteria: syntax, completeness, clarity and coherence, and relevance.


Additionally, there is also significant reduction in nonsensical hallucinations, contradictions and repetitions for the fine-tuned model for Nepali. This shows that fine-tuning likely helped the model better understand Nepali texts and related linguistics nuances, which may not have been well-captured in the original pre-trained model. However, there is an increase in factual hallucinations post fine-tuning, which could be because the model overfit on specific factual details during the fine-tuning.
The fine-tuned model Hindi also shows less nonsensical and repeated responses than the baseline model. Note, that we don’t observe an increase in factual hallucination for Hindi, which we observed in Nepali but we see an increase in contradictions. Since, we used the translated version of Alpaca Dataset for respective model fine-tuning, it could mean that the translated dataset to Nepali and Hindi might contain more ambiguities or inconsistencies, which are then propagated during fine-tuning, causing factual hallucination, in case of Nepali and contradictions in case of Hindi to increase.
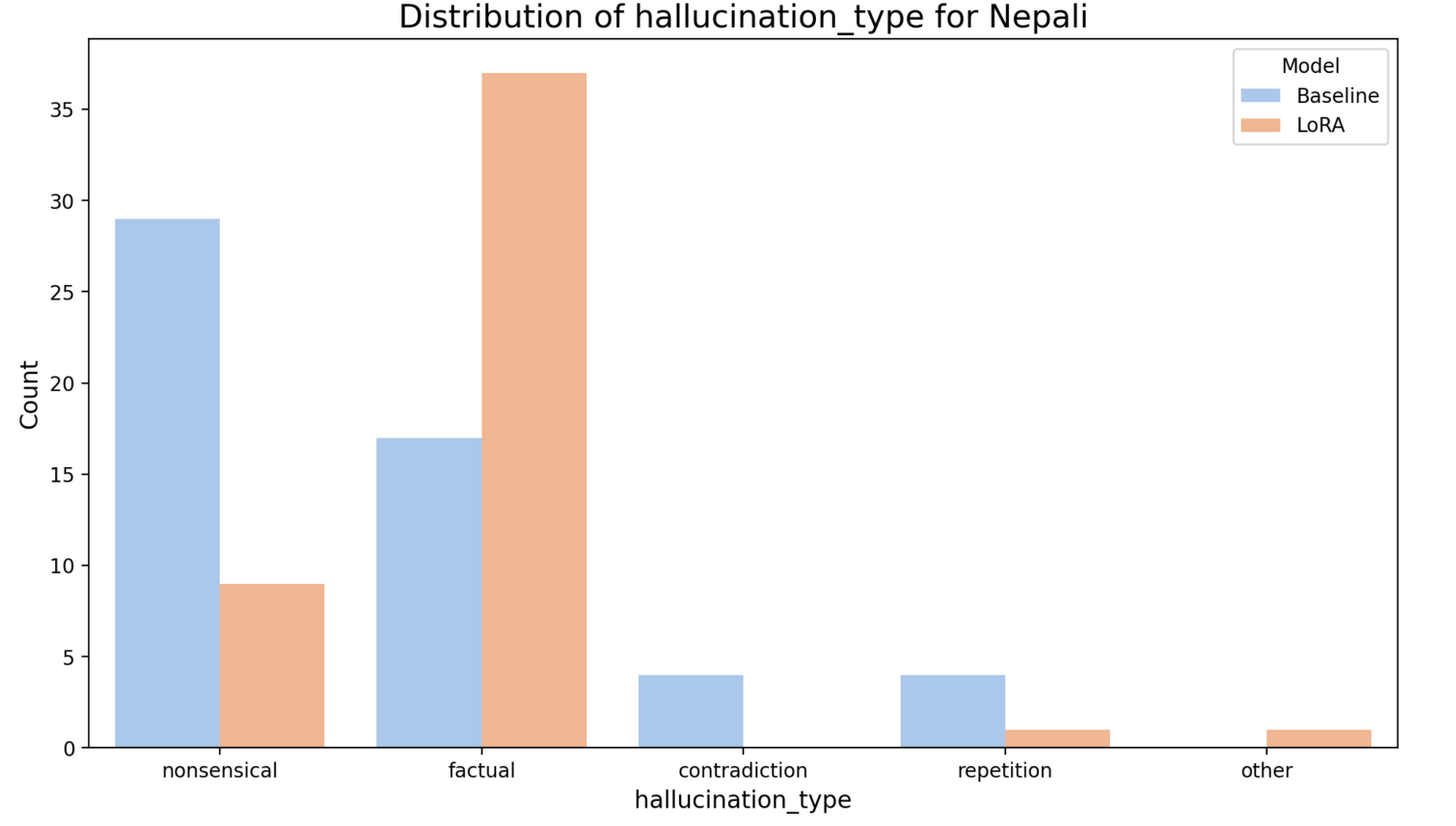
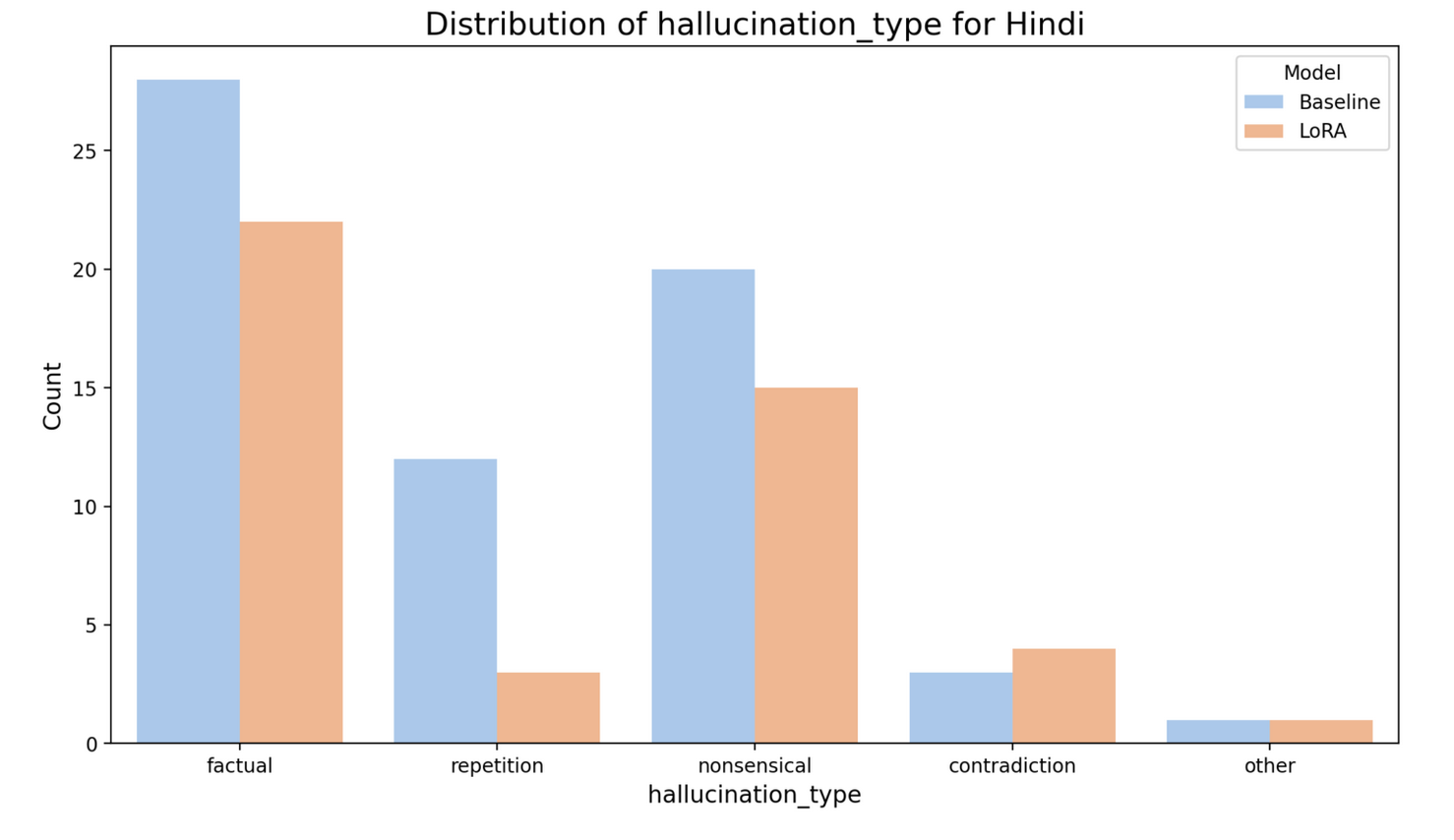
Limitations and Future Work
While we observed significant performance gain for both Hindi and Nepali text generation using QLoRA finetuning, there are several limitations and scope for future work. The quality of fine-tuning dataset greatly improves the quality of generation. Since we are using a translated dataset, the errors during translation may be amplified during LoRA finetuning. A human curated, high quality and diverse dataset, for both fine-tuning and evaluation, should be a consideration for future work. In the quick sets of experimentation in this work, we used GPT as a judge to score responses, having a human grade the outcome of the models would be helpful in providing better insights into the model's performance. Additionally, different techniques to regularize the fine-tuning process, such as incorporating adversarial training and controlled generation could help mitigate factual hallucinations and contradictions.
Acknowledgements
On this blog, I collaborated with Shilpa Bhandari, who helped me with preliminary analysis of baseline results and finetuning/analysis of Hindi results.
Shilpa graduated with a Bachelors in Mathematics and Bachelors in Computer Science from Youngstown State University, Ohio in 2021. She currently works as a data analyst reporting on schedule and financial data at a utility company. As the founder of the Nepalese in Tech Discord community with 1000+ members, she is passionate about technical research involving the Nepalese language and the Nepalese community.