

Exploring multilingual aspects and vocabulary of LLaMA 3 compared to LLaMA 2
This is the first part of a series where I will discuss the multilingual abilities of the LLaMA 3 model.

Meta AI launched LLaMA 3 earlier on Thursday: LLaMA-8B and 70B models. While I can't wait to conduct a comprehensive study of the model's multilingual abilities, in this introductory blog post, I will briefly discuss how it differs from LLaMA 2. Much of the information shared here is already available as part of the model's release notes. However, this post will narrow down the information shared by Meta from a multilingual perspective. Additionally, we will also explore LLaMA 3's vocabulary and tokenizer and compare it to those of LLaMA 2.

Summary of the updates
“The most capable openly available LLM to date”, - meta
8B and 70B parameter models, state-of-the-art models at those scales
Improved tokenizer with a vocabulary of 128K tokens
Grouped Query Attention in both models
8,192 sequence lengths
Pretrained on 15 trillion tokens, with 4X more code and 5% non-English data
Focus on multilingual capabilities
Both LLaMA 3 8B and 70B that were released on Thursday are text-based models and these models improve significantly in comparison to their predecessor, LLaMA 2. In this blog, I will only discuss the following enhancements highlighted in the LLaMA 3 release:
Improved Tokenizer: LLaMA 3 features an updated tokenizer with an expanded 128K vocabulary compared to LLaMA 2's 32K vocab. The new tokenizer has up to 15% fewer tokens compared to LLaMA 2.
Larger Training Data: LLaMA 3 was trained with 15 trillion tokens in contrast to LLaMA 2 which was trained with 2 trillion tokens.
LLaMA 3 training data contains 4 time more code
LLaMA 3 contains 5% of the total data is in non-english language
LLaMA 2 contains 10.3% non-English data but 8.38% is classified as unknown which is partially made with coding data.
While the LLaMA 2 paper explicitly listed "Use in languages other than English" as out-of-scope, the LLaMA 3 release blog indicates they have specifically prepared for upcoming multilingual use cases by including over 5% high-quality non-English data spanning more than 30 languages in the pretraining dataset for LLaMA 3.
Expanded vocabulary from 32k to 128K
LLaMA 3 uses a vocabulary that is nearly four times larger than LLaMA 2's vocab. This substantial increase in vocabulary results in a considerably larger embedding matrix, consequently increasing the overall model parameters from 7 billion in LLaMA 2 to 8 billion in LLaMA 3.
Considering LLaMA 3 was trained with more multi-lingual data, let's explore how this increased exposure to data in different languages might be reflected in its vocabulary distribution.
Note: These subwords were categorized into a specific language class using langdetect.
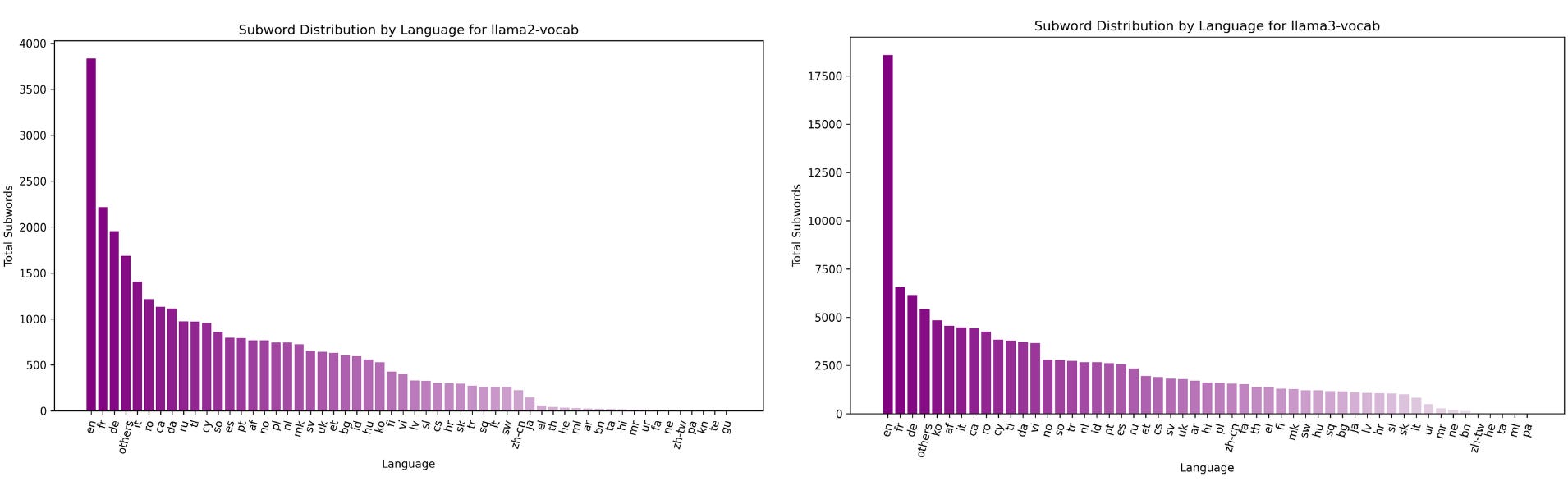
The overall shape of the distribution of subwords across languages follows power-law distribution for both LLaMA 2 (left) and LLaMA 3 (right). The LLaMA 3 vocab demonstrates impressive language coverage. It includes a wider set of languages with higher subword count. Notably, it includes several languages with subword counts between 5,000 and 10,000, signifying stronger support for multiple high-resource languages. However, there is still a large number of languages with fewer than 2,500 subword types, suggesting the need to improve the representation for low-resource languages.
Tokenization times
While LLaMA 3 offers a wider language coverage in its vocab, it comes at the cost of slower tokenization times. Moving from LLaMA 2 to LLaMA 3 results in a significant increase in tokenization time – from a median time of 0.28 to 0.81 seq/s. This can be seen in the below diagrams, as the curve for both English and other languages has moved towards the right.


For both LLaMA 2 and LLaMA 3, the average and median tokenization times are consistent between English and other languages like Hindi and Nepal. The distribution for LLaMA 2, overall, is taller and slimmer, which implies a narrower range for tokenization times in comparison. This also means that LLaMA 2 has a more consistent and efficient tokenization time across sequences. This is not only true for English but other languages as well.
This might not be a serious issue overall, depending on how much time tokenization takes in the entire model execution pipeline. We will take a closer look at this in a subsequent post.
Tokenization trends across languages
The following curves show the distribution of token lengths for English, Hindi and Nepali for LLaMA 2 and LLaMA 3 tokenizers. Both tokenizers have taller and narrower curves for English. The median token lengths for English is similar (14 v/s 13) for LLaMA 2 and LLaMA 3, which shows that there's consistency in tokenization lengths across versions for English.


In comparison, for both LLaMA 2 and LLaMA 3, Hindi and Nepali have a shorter and wider token lengths distribution curve. This suggests Hindi and Nepali texts are tokenized into longer token lengths by both versions of LLaMA. However, there's a noticeable difference in median token lengths for Hindi and Nepali, 64 for LLaMA 2 to 33 for LLaMA 3. Also, the curves more flat and wide for LLaMA 2 in comparison. This indicates that LLaMA 3 seems to have learned from the additional multilingual data to better segment sequences in languages other than English. Given that Nepali and Hindi are morphologically more complex than English, this shows that LLaMA 3 has an improved ability to handle complex languages.
Conclusion
In conclusion, LLaMA 3 offers a substantial leap in vocabulary size and language coverage compared to LLaMA 2. This expansion improves handling of morphologically complex languages but comes at the cost of less efficient tokenization times. LLaMA 3 demonstrates the benefit of multilingual data, achieving more accurate segmentation in languages like Hindi and Nepali. These findings show a trade-off between multilingual tokenization capabilities and processing speed. However, the regression in tokenization time might not be as significant when we look as the inference time for the entire pipeline.
What Next in This Series?
Dive deeper! In the next parts of this series, we will dive deeper into different components of the LLaMA 3 model and examine each component from a multi-lingual lens. This will help us understand how LLaMA 3 handles different languages.
We will also fine-tune LLaMA 3 8B for Hindi and Nepali. This will help us assess its capabilities for non-latin languages. In particular, fine-tuning for Nepali, we will also get insights into how effectively, or if at all, adapt LLaMA 3 to low-resource languages.
In addition to blogs, I will prepare notebooks and visualizers for each component I look into in this series. So stay tuned!