

Aligning LLMs - Fine-Tuning LLaMA with SFT and RHLF
Part 3: Understanding LLM alignment with Supervised Fine-Tuning and Reinforcement Learning from Human Feedback

Large Language Models (LLMs) like LLaMA are pretrained with large amounts of unlabeled text with self-supervised training objectives like next token prediction. Pretraining LLMs with self-supervised objectives allows the model to learn rich representation in language and across different domain from the large volume of unlabeled text that is readily available. However, such pretrained models might not be optimized for specific downstream tasks, domains or desired behaviors and this is where aligning large pretrained language models come into play.

This is the third post of the blog series on LLaMA family of models. In part one, we briefly compared LLaMA 2 and LLaMA 3. We additionally discussed the improvements in LLaMA 3, particularly focusing on the improved tokenizer along with increased focus on multi-lingual ability of the third iteration of the model.
Exploring multilingual aspects and vocabulary of LLaMA 3 compared to LLaMA 2

Meta AI launched LLaMA 3 earlier on Thursday: LLaMA-8B and 70B models. While I can't wait to conduct a comprehensive study of the model's multilingual abilities, in this introductory blog post, I will briefly discuss how it differs from LLaMA 2. Much of the information shared here is already available as part of the model's release notes. However, this…
Part two of the series discusses the architecture of the LLaMA family of models along with the modifications that are made on top of the original transformer model and the techniques employed for efficient pretraining of the LLaMA models.
The LLaMA Family of Models, Model Architecture, Size, and Scaling Laws

Since February 2023, Meta has open-sourced three versions of their LLaMA language model. This has enabled thousands of people in the AI and NLP communities to explore and build upon the LLaMA models for their use-cases. On April 18, 2024, Meta open-sourced
In this post, we will be focusing on methods used in aligning LLMs to specific tasks and desired behaviors. We will also walk through fine-tuning details, including Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) discussed in the LLaMA 2 paper. Additionally, we will discuss the LLM safety approaches employed by LLaMA 2 model during the fine-tuning process. Fine-tuning details for LLaMA 3 is out of scope for this post, as the paper for the model is not out yet.
RECAP: Large Language Models
Large language models (LLMs) are deep neural network models that are trained on a large corpora of text to understand and generate natural language. Transformer, introduced in the 2017 paper “Attention Is All You Need” is now the most widely adopted architecture for language modeling. The following resources will give a comprehensive understanding of language modeling and transformer based language models. This makes an important foundation for the rest of the blog.
Customizing and Aligning LLMs
Training LLMs involves multiple stages. First, pretraining the models on a large unlabeled corpus using self-supervised techniques like next token/sentence prediction and/or masked language model. Pretraining helps models learn rich representations about language and acquire general knowledge across multiple domains without relying on explicit annotations. However, pretraining LLMs is computationally expensive and unattainable to many individuals and organizations. These pretrained LLMs, at many times, also need to be adapted for specialized goals and use-cases.
“According to AI Index estimates, the training costs of state-of-the-art AI models have reached unprecedented levels. For example, OpenAI’s GPT-4 used an estimated $78 million worth of compute to train, while Google’s Gemini Ultra cost $191 million for compute.
- Artificial Intelligence Index Report 2024 by HAI Stanford
After the initial pretraining, LLMs are fine-tuned, or sometimes further pretrained to customize them for specific tasks, domains, or goals. In addition to adapting the LLMs to specific tasks and domains, fine-tuning allows models to align with desired behaviors and safety considerations. This is achieved through techniques like Supervised Fine-Tuning (SFT) and/or Reinforcement Learning from Human Feedback (RLHF), which are computationally cheaper in comparison to pretraining but time-consuming given these processes typically require high-quality and human curated datasets.
A three-step alignment process described in the InstructGPT paper, is a widely adopted method to train language models to exhibit desired behaviors. The first step supervised fine-tuning (SFT) involves teaching the model to follow instructions. Step two and three involve learning from human feedback what a desired behavior is and optimizing the model to produce outputs to align with the desired behaviors. Note that only steps 1 and 3 involve modifying model parameters, in the second step the data to train the reward model is created and the reward model that helps score the responses during RLFH fine-tuning is trained.
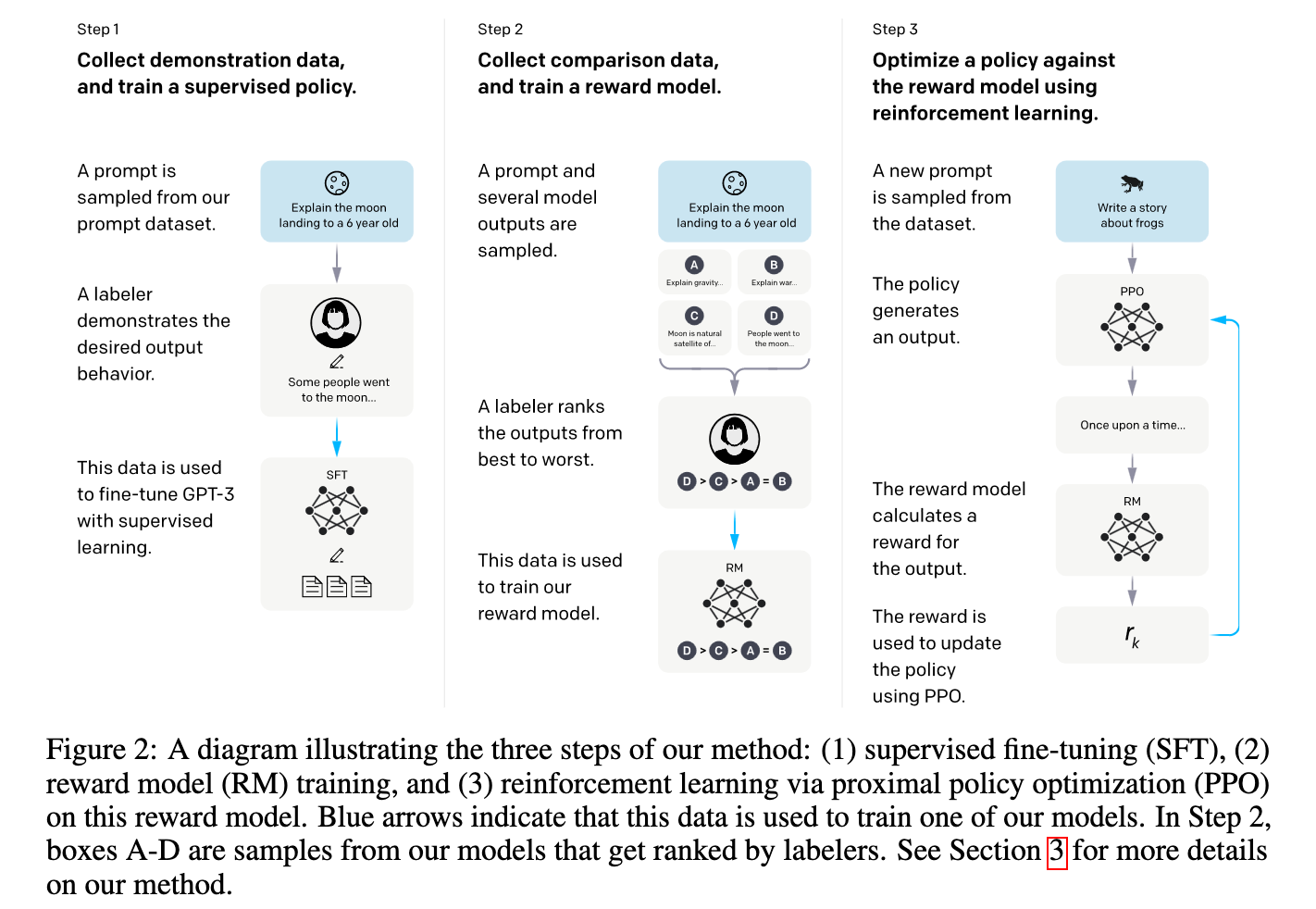
LLaMA 2 chat was aligned towards dialog-style instructions using the three-step process. It was aligned for helpfulness, i.e “how well Llama 2-Chat responses fulfill users’ requests and provide requested information,” and safety, which refers to “whether Llama 2-Chat’s responses are unsafe.” The LLaMA 3 release note leaves out the fine-tuning details but speculating based on the information in the note, it seems to follow the similar process as LLaMA 2 chat.

Supervised Fine-Tuning
Supervised Fine-Tuning (SFT) is a technique for adapting general pretrained LLMs to a specific downstream task, domain, or application. It involves further training a pretrained model using a smaller and labeled dataset with a next-token prediction objective, similar to the original pretraining. Since, SFT uses a high quality curated dataset to update the model’s parameters for a specialized task/application, it is called “supervised fine-tuning.”
“Quality Is All You Need.
“We found that SFT annotations in the order of tens of thousands was enough to achieve a high-quality result.
For the LLaMA 2 chat model, the authors initially conducted SFT with publicly available instruction tuning data. However, they discovered that despite its large size, this dataset lacked diversity and quality, which are needed to produce quality results. After analyzing the results from this initial SFT phase, they decided to fine-tune the model using a smaller but high-quality dataset. Their findings show that using a small and curated high-quality dataset is enough to produce high-quality results. They also highlight that "the output from the fine-tuned model were often competitive with SFT data handwritten by human annotators, which is why they stopped annotating data for SFT at 27K and decided to devote more annotation effort to preference-based annotation for RLHF. Similarly in the LLaMA 3 release note the share a similar observation where the biggest gains in model quality came from the quality of data.
“Some of our biggest improvements in model quality came from carefully curating this data and performing multiple rounds of quality assurance on annotations provided by human annotators.
LLaMA 2 chat model was fine-tuned for two epochs. During this fine-tuning process, each sample was constructed by concatenating a prompt and its corresponding response, separated by a special token. The model was then trained using the next sentence prediction objective and the loss on prompt tokens were not considered during back propagation.
Reinforcement Learning from Human Feedback (RLHF)
The next two steps in the three-step process for model alignment focuses on training the model to select optimal response. A prompt can have multiple responses, give this the goal is to teach the model to distinguish between the responses and choose the best response. The curated data used in SFT training only tells the model what a plausible response looks like, it does not teach the model which of the responses is the best one. This limitation in SFT is addressed by reinforcement learning from human feedback (RLHF), where a model is fine-tuned directly on human feedback on the model’s responses.
The two steps in RLHF includes:
Train a reward model, which is used to score responses.
Optimize the pretrained or supervised fine-tuned LLM to generate responses that receive high scores from the reward model.
Reward Model (RM)
For a (prompt, reward) pair, a reward model outputs a score based on the alignment objective. In LLaMA 2, there were two reward models, one for assigning helpfulness score and other for safety score. Sometimes a single reward model can be trained for multiple alignment objectives if the objectives are compatible. The decision to use a single or multiple reward objectives depends on the alignment goals and if those goals can be meaningfully combined together. Also, additional factors like compute and end-user requirements may also play a role in the decision-making.
Data collection. The overall data curation process would involve annotators writing the prompts based on the alignment objective, like helpfulness and the LLM would generate multiple responses to the prompt. These responses are then reviewed by the annotators and are scored or a preferred response is marked, depending upon the requirement. While training the model to assign a score in itself is not a challenging task, the process of curating a dataset for each objective with consistent scores among the human annotators is difficult. For this reason, some approaches exclude the scoring the response, instead the annotators are asked to choose the best response among the choices. The preferred response or score for the response is decided based on how close the response is to the alignment objective.
The human preference data curated for LLaMA 2 consisted of pairwise comparisons. Each instance of the comparison data included a prompt, a preferred response, and a rejected response. The annotators also rated the degree of preference using a four-point scale: significantly better, better, slightly better, or negligibly better. The data was collected in batches and RLHF models were fine-tuned iteratively.

Reward model training. The reward model is trained on the human preference dataset to output a preference score, which basically indicates the quality of the model’s output on specific alignment objectives. To achieve this model’s classification layer used in the next token prediction is replaced by a regression layer and the model is optimized using a loss function. This loss function is designed such that it incentivizes the model to assign higher scores to preferred responses and lower scores to non-preferred ones.
In the LLaMA 2, two reward models were trained, one for helpfulness and another for safety. Each model was initialized from pre-trained chat model checkpoints and was trained by first converting the pairwise preference dataset into binary label ranking format, where each pair consisted of a "chosen" (preferred) and a "rejected" (less preferred) response. Then the reward model was trained using binary ranking loss function, which penalizes the model when it assigns higher score to a rejected response. This effectively teaches the model to favor the preferred response over the rejected one. The binary ranking loss function follows form:
Since the pairwise preference data collected for reward modeling in LLaMA 2 was also annotated on a four-level preference scale, a margin component, m(r), was added to to the binary ranking loss to help the reward model to assign more distinct scores with larger gaps for generation that have bigger differences.
In addition to the pairwise preference data that was curated for LLaMA 2, the authors also used open source preference data for reward model training because they did not observe any negative transfer from using the public dataset in the performance of the reward model. The authors also claimed that incorporating open source data could allow better generalization and mitigate the risk of reward hacking, which would occur when the LLaMA Chat model exploits the weaknesses of the reward functions and artificially inflate the score without actually improving the model performance.
“However, in our experiments, we do not observe negative transfer from the open-source preference datasets. Thus, we have decided to keep them in our data mixture, as they could enable better generalization for the reward model and prevent reward hacking, i.e. Llama 2-Chat taking advantage of some weaknesses of our reward, and so artificially inflating the score despite performing less well.
The reward models were trained for one epoch over the training data with the same optimizer parameters as for the base model.
Iterative RLHF fine-tuning
During RLHF, given a prompt, the model generates a response that is scored by the Reward Model (RM) trained in step 2 of the three-step model alignment process. As the model is fine-tuned to maximize these scores, it can diverge from its original behavior due to factors such as overfitting to reward signals, exposure bias, limited training data, or inaccurate scoring by the RM. This divergence could potentially compromise the broad knowledge base originally acquired during the pretraining phase. Therefore, it is crucial to ensure that the model trained during RLHF does not perform worse than or deviate from its original behavior.
Proximal Policy Optimization (PPO). is a standard RL algorithm that helps constraint the model such that the model fine-tuned in this stage does not deviate too much from the original behavior. One of the ways PPO ensures that the model does not deviate too far, a KL divergence penalty is added to the objective.
Here are some papers that are helpful in understanding the PPO algorithm:
In addition to PPO, in LLaMA 2 the authors also explored rejection sampling for RLHF.
Rejection sampling involves generating multiple candidate responses for each prompt and selecting the one with the highest reward score for the gradient update. In LLaMA 2, rejection sampling was done with the 70B LLaMA 2 Chat model. All the smaller models were fine-tuned on rejection sampled data from 70B LLaMA 2 Chat model, effectively distilling the capabilities of the larger model into the smaller ones. The authors trained 5 successive versions for RLHF models, RLHF-V1 to RLHF-V5. In LLaMA 2, instead of fine-tuning the model solely on the best candidate response from the previous iteration, the authors included the best candidate from the current iteration along with top-performing samples from all prior iterations. This choice was made to address regression that they observed in experiments where they sampled the best candidate from the preceding iteration only.
Also until RLHF-V4, only rejection sampling was used for fine-tuning. Subsequently, they applied PPO on top of rejection rampling to refine the model checkpoint obtained from rejection sampling before proceeding with further sampling.
The objective being optimized is to maximize the expected reward with respect to the policy π as:
The reward function used during PPO is:
Note that the second term in the final objective contains a KL divergence penalty that helps constrain the model such that it does not diverge from the original policy π_0. Also, Rc is a piecewise combination of the safety (Rs) and helpfulness (Rh) reward models.
For prompts that are tagged as potentially eliciting unsafe responses, Rc prioritizes scores from the safety model. If the safety score for response to a prompt is either explicitly marked as unsafe or scores below a threshold of 0.15, Rc favors the score from the safety reward model over the helpfulness one.
All the RLHF models were fine-tuned between 200 and 400 iterations and early stopping was applied based on the evaluations on held-out prompts.
Safety fine-tuning in LLaMA 2
Safety was one of the two primary alignment objectives in LLaMA 2. The safety fine-tuning process used is similar to the general fine-tuning methods with additional efforts to ensure that the models avoid displaying any unsafe behaviors. To address this, adversarial prompts and safe demonstrations were included in the SFT and RLHF processes. The RLHF pipeline was also refined with context distillation by prefixing a prompt with a safety instruction, such as “You are a safe and responsible assistant,” and then fine-tuning the model on the safer responses without the safety instruction. Additionally, the annotation team was guided to create adversarial prompts along two dimensions: risk categories and attack vectors.
“we design instructions for our annotation team to create adversarial prompts along two dimensions: a risk category, or potential topic about which the LLM could produce unsafe content; and an attack vector, or question style to cover different varieties of prompts that could elicit bad model behaviors.
They identified three risk categories: illicit and criminal, hateful and harmful activities, and unqualified advice. Several attack vectors were explored including psychological manipulation, logic manipulation, syntactic manipulation, semantic manipulation, perspective manipulation, and non-English languages, among others. This comprehensive approach to data curation and RLHF fine-tuning of the model was done to systematically identify unsafe behaviors and train the model for safety and reliability.
Conclusion
Aligning LLMs is important for adapting pre-trained LLMs to specific tasks and desired behaviors. While the standard three-step model alignment process may seem straightforward, it is an involved process that requires a comprehensive fine-tuning dataset, rigorous evaluation processes and multiple training iterations to ensure that the model's performance aligns with intended goals. Additionally, the concept of desired behaviors in LLMs seems to be evolving with increased emphasis on safety.
In the next post in this series, we will work on a Low Rank Adaptation (LoRA) fine-tuning of the LLaMA 3 model for Nepali and Hindi. We'll examine the model's multilingual capabilities and assess its performance on low-resource languages like Nepali. So stay tuned!
It's interesting how you highlight the realy crucial role of alignment. Thanks for this.