

The LLaMA Family of Models, Model Architecture, Size, and Scaling Laws
Part 2: A look into the Meta's LLaMA family of models before we deep-dive into each components from multi-lingual lens

Since February 2023, Meta has open-sourced three versions of their LLaMA language model. This has enabled thousands of people in the AI and NLP communities to explore and build upon the LLaMA models for their use-cases.
On April 18, 2024, Meta open-sourced LLaMA 3, which they claim is "the most capable openly available large language model to date," backed by its performance across multiple benchmarks. In my pervious post, we briefly talked about and compared LLaMA 2 and LLaMA 3. In the blog, we also touched upon the focus on the multilingual ability in the latest release. Additionally, we discussed the expanded vocab and improved tokenizer in LLaMA 3.

In this post, we will discuss the architecture of the LLaMA family of models and focus on the modifications that are made on top of the original transformer model. In addition, we will also discuss how the second and third iterations of the model differ from LLaMA 1. Note: since LLaMA 3 paper is not out yet, the comparison will be limited to what was released as a part of the model’s release note.
Fine-tuning methodology and LLM safety employed by LLaMA 2 and LLaMA 3 are out of scope of this blog post.
Large Language Models
Large language models (LLMs) are deep neural network models that are trained on large corpora of text to understand and generate natural language. Transformer, introduced in the 2017 paper “Attention Is All You Need” is now the most widely adopted architecture for language modeling. The following resources will give a comprehensive understanding of language modeling and transformer based language models. This makes an important foundation for the rest of the blog.
Now, lets look into the LLaMA family of models.
Model Architecture
The LLaMA family of models are auto-regressive decoder-only models. These models are based on the transformer architecture with some modifications. We will start by looking into the LLaMA 1 architecture and discuss the differences it has in comparison to the transformer model. Then, we will build up from there up to LLaMA 2 and LLaMA 3 models, comparing how the newer iterations of the model improves on the previous ones.
LLaMA 1
LLaMA 1 works by predicting the next token given a sequence of input tokens, similar to any other transformer-based decoder-only models. However, LLaMA 1 incorporates several architectural modifications that set it apart, including pre-normalization of input with RMSNorm, use of SwiGLU activation function and rotary positional embedding (RoPE).
Pre-normalization of Input
LLaMA 1 and the subsequent iterations of the model use pre-normalization to enhance model training stability and performance. Normalization is applied to the input of each sub-layer, unlike the original transformer model where the normalization is applied after each sub-layer.
Pre-normalization in deep models like LLaMA is motivated by its ability to facilitate more efficient gradient flow during the backpropagation process by allowing error gradient to flow directly from top to bottom layers without passing through the normalization operations. The residual connection acts as a bypass, mitigating the risk of vanishing or exploding gradients in deep networks.
In Learning Deep Transformer Models for Machine Translation, the authors find that pre-normalization allows more efficient training of deeper Transformer models.
“More specifically, we find that prenorm is more efficient for training than post-norm if the model goes deeper.
LLaMA also uses RMSNorm (Root Mean Square Normalization) as the normalization function instead of the LayerNorm. In deep neural networks, changing parameters in one layer can cause shifts in the input distributions for subsequent layers. These internal distribution shifts is also known as internal covariate shift and can make it more challenging for models, especially those with a large number of layers, to learn and converge. LayerNorm stabilizes the training of deep neural network by addressing internal covariate shift but introduces additional overhead, which becomes substantial for deeper networks. LayerNorm has two key properties:
re-centering invariance, which makes the model insensitive to shift noises in inputs and weights, and,
re-scaling invariance, which preserves output representations when inputs and weights are randomly scaled.
Authors in Root Mean Square Layer Normalization show that re-centering has little impact on stabilizing model training and re-scaling alone gives similar or more effective results when training deeper neural networks.
“Although RMSNorm does not re-center the summed inputs as in LayerNorm, we demonstrate through experiments that this property is not fundamental to the success of LayerNorm, and that RMSNorm is similarly or more effective.
Additional reading materials for normalizations in deep neural networks:
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Transformers without Tears: Improving the Normalization of Self-Attention
Demystifying Normalization in Deep Learning - Easy Visualizations and PyTorch Code
SwiGLU Activation
Inspired by PaLM: Scaling Language Modeling with Pathways, LLaMA uses SwiGLU (Sigmoid-Weighted Linear Unit) activation.
“SwiGLU Activation – We use SwiGLU activations (Swish(xW )· xV ) for the MLP intermediate activations because they have been shown to significantly increase quality compared to standard ReLU, GeLU, or Swish activations (Shazeer, 2020) - Section 2
SwiGLU combines Swish and GLU (Gated Linear Unit) activations. GLU is a component-wise product of two linear transformations on input, where one is sigmoid-gated:
The Swish activation function, introduced in the paper SWISH: A SELF-GATED ACTIVATION FUNCTION, is a smooth, non-monotonic activation that has been shown to outperform or match the widely-used ReLU activation across various of deep learning models. It defined by:

SwiGLU introduced in GLU Variants Improve Transformer is defined by:
where, W, b, and β is a trainable parameter.
In the paper, GLU Variants Improve Transformer the author experimented with different variations of GLU and showed that variants of GLU (including SwiGLU) shows improvements in quality compared to ReLU or GELU activations.
“We test these variants in the feed-forward sublayers of the Transformer [Vaswani et al., 2017] sequence-to-sequence model, and find that some of them yield quality improvements over the typically-used ReLU or GELU activations. - Abstract
“We offer no explanation as to why these architectures seem to work; we attribute their success, as all else, to divine benevolence. - Conclusion
Evaluating the performance impact of one activation function over another is a challenging task. It is difficult to study activation functions in isolation and pinpoint the exact reasons why one function outperforms another. Several variables can influence the training process, making it hard to draw definitive conclusions. However, certain properties of the SwiGLU activation function may offer insights into its potential advantages. SwiGLU is a smoother function in comparison which could allow better optimization and convergence, while its non-monotonic nature enables capturing complex non-linear relationships. Additionally, SwiGLU uses a gating mechanism that selectively activates neurons based on the received input, reducing overfitting and improving generalization.
“Our experiments show that Swish consistently outperforms or matches the ReLU function on a variety of deep models. While it is difficult to prove why one activation function outperforms another because of the many confounding factors that affect training, we believe that the properties of Swish being unbounded above, bounded below, non-monotonic, and smooth are all advantageous. - Section 2.1
Rotary Positional Embeddings (RoPE)
Positional embedding help transformers to distinguish between the same word at different positions in a sequence. The LLaMA family of models uses RoPE instead of absolute positional embeddings. Absolute positional embeddings adds the position information by adding position vector to token embeddings and it does not take into account how one position in the sequence relates to another.
In contrast, Rotary Positional Embedding (RoPE), introduced in ROFORMER: ENHANCED TRANSFORMER WITH ROTARY, applies rotations to word vectors based on where it occurs in the sequence. Instead of directly adding positional embeddings to word vectors, RoPE rotates the word vectors by an angle proportional to their position. Specifically, if θ is the degree by which a word vector is rotated, a word occurring at position m is rotated by m × θ. This rotation preserves the advantage of absolute positional embeddings by maintaining a unique representation for words at each position. Additionally, RoPE gains the benefit of relative positional embeddings, as two word vectors are rotated by the same amount as long as the distance between the two words remains constant.
Since RoPE maintains a contextual relationship between two tokens, it is able to capture long range dependencies enabling improved performance and faster convergence in tasks involving long texts/documents.
“Notably, RoPE enables valuable properties, including the flexibility of sequence length, decaying inter-token dependency with increasing relative distances, and the capability of equipping the linear self-attention with relative position encoding. - abstract
LLaMA 2 and LLaMA 3:
The LLaMA family of models share majority of its architecture. Following are how the three iterations of the model differ from one another:
The context length of LLaMA 1 is 2K tokens, that of LLaMA 2 is 4K and the latest LLaMA 3 has 8K context.
LLaMA 2 and LLaMA 3 adopts Group Attention Query (GQA). LLaMA 2 only uses GQA in its larger parameter models, while LLaMA 3 uses it on all versions.
Grouped Attention Query (GQA) in LLaMA 2 and LLaMA 3
Traditional Multi-Headed Attention (MHA) used by the Transformers have a high memory overhead as all attention keys and values need to be loaded during each decoding step. Grouped Query Attention addresses that overhead by grouping query heads into G groups such that each group shares a key and value. This reduces computational and memory overhead and allows faster inference time while maintaining the quality on par with the MHA models.
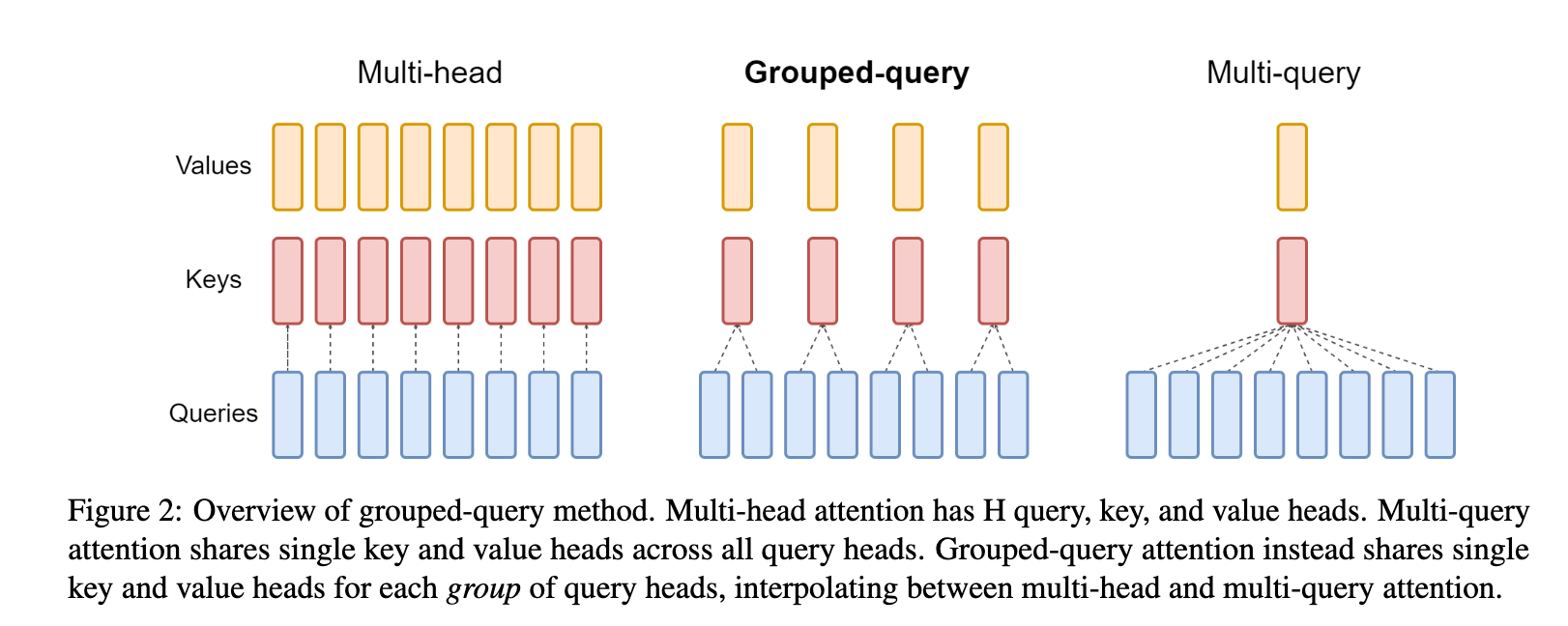
“"Grouped-query attention divides query heads into G groups, each of which shares a single key head and value head.
- GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Efficient Pretraining
The self-attention mechanism used in Transformers can become a bottleneck in terms of computational time and memory usage, when training LLMs with long sequences. This is because the time and memory complexity of standard self-attention scales quadratically with the sequence length, making it increasingly expensive for longer sequences. To address this issue, LLaMA 1 and its variants employ two key optimizations: memory efficient attention and FlashAttention.
“First, we use an efficient implementation of the causal multi-head attention to reduce memory usage and runtime. This implementation, available in the xformers library,2 is inspired by Rabe and Staats (2021) and uses the backward from Dao et al. (2022).
- LLaMA 1
Memory efficient attention: In causal LLMs like LLaMA, the self-attention mechanism does not need to attend to future (mask) tokens, so using causal multi-head attention can reduce memory usage and runtime. LLaMA uses an efficient implementation of causal multi-head attention that avoids explicitly creating and storing large attention mask tensors. It leverages an AttentionBias object to hardcode the mask pattern into the computation kernels, leading to substantial memory savings, particularly for long input sequences.

FlashAttention: LLaMA training also used backward from FlashAttention algorithm, which is an algorithm that optimizes the self-attention computation in Transformers. The optimization in FlashAttention is achieved by utilizing the memory hierarchy and intelligently mapping the computation to minimize memory transfers. It does so through two key techniques: tiling and recomputation. Tiling splits input sequences and attention matrices into smaller blocks/tiles, enabling computations to reside in fast on-chip memory while minimizing slow off-chip memory accesses. Recomputation avoids storing and transferring large intermediate attention matrices between memory levels by recomputing them on-the-fly during the backward pass using statistics stored from the forward pass.
“To further improve training efficiency, we reduced the amount of activations that are recomputed during the backward pass with checkpointing. More precisely, we save the activations that are expensive to compute, such as the outputs of linear layers.
- LLaMA 1
Activation Checkpointing: In addition, LLaMA also leverages activation checkpointing. They save the activations that are expensive to compute, such as the outputs of linear layers instead of recomputing them during the backward pass.
Pretrained with public dataset
The LLaMA family of models were all trained with only publicly available datasets. The training dataset for all three variants is composed majorly of English datasets. Starting with LLaMA 2 the focus has shifted heavily towards using higher quality and larger dataset to train the models. Data from sources known to contain personal information was removed from the training data and the data from factual sources were upsampled for model training.
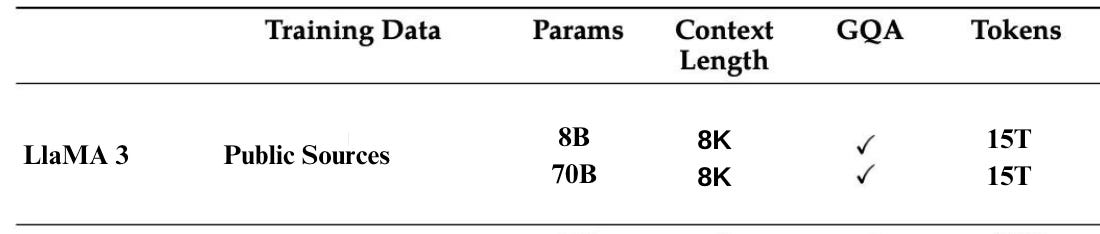
LLaMA 3 was pretrained on over 15T tokens, again all open source datasets. With LLaMA 3, the focus has also shifted towards multilingual use cases and in that effort the training data for LLaMA 3 contains 5% high-quality non-English data spanning more than 30 languages. It also contains 4 time more code in comparison to LLaMA 2.
Here are the details on the size of pretraining dataset for each variant of LLaMA models so far:

Scaling laws
One thing that I was excited about in the LLaMA 1 paper and their subsequent works was their focus on optimizing the inference budget by training the smaller models on larger number of tokens. Smaller models with faster inference speed would mean people can use LLMs on-device, which would ensure:
Improved privacy as user’s personal data remains on device and is not sent to remote servers.
Access to LLMs in offline mode, especially useful in remote places with limited internet connectivity.
Better personalization as users can fine-tune and personalize the models to their data and use-cases without sharing their personal information to the third-party servers.
Faster inference time as it would no longer be necessary to send data to and from remote servers.
Seamless integration into on-device user applications.
Personally, I am GPU poor and so is the majority of the world, smaller models that are cheaper at inference is useful for individuals like me who have limited computational resources available.
“The focus of this work is to train a series of language models that achieve the best possible performance at various inference budgets, by training on more tokens than what is typically used. - Introduction
- LLaMA 1
The smallest LLaMA 1 7B was trained on 1T tokens, LLaMA 2 7B was trained on 2T tokens and their latest LLaMA 3 8B was trained with 15T tokens, which is 75 times larger than the Chinchilla’s compute-optimal threshold of 200B tokens recommended for a 10B model. The latest results for LLaMA 3 across several benchmarks demonstrate that continuing to scale up the amount of training data and training for longer time can yield significant performance gains, even for relatively small model sizes, when optimizing for the inference budget rather than just the training budget.
You can read more on scaling laws here:
Stay Tuned!
The consistent emphasis of the LLaMA work on the cheaper inference budget is promising, especially for enabling wider access to large language models across low-resource languages and use-cases - a domain I'm interested in. I am looking forward to do work more with LLaMA and compare it against other small and open source models. Next in this series, we will talk about each (where it makes sense) components in the LLaMA models from the multilingual lens. When we get to fine-tuning the LLaMA 3 ourself, we will dive-deeper into the fine-tuning methodology and LLM safety measures employed by LLaMA models.