



While proofreading the "How LLMs Break Down Language from Text to Tokens" section from my last blog, Nolan asked me a thought-provoking question: "Then what would the cost of ideas for ideographic languages be?" His question highlighted the significant differences between two writing systems: ideographic languages, where characters represent ideas, and orthographic languages, where characters represent sounds. This further prompted an investigation into whether this distinction affects the overall cost of ideas for large language models (LLMs).
In this blog post, we will try to answer Nolan's question and explore the following:
Ideographic vs. Orthographic Languages: Explore the fundamental differences between ideographic languages like Chinese and Japanese and orthographic languages like English and Nepali.
The Trade-Off between Conciseness and Digital Footprint: We will briefly explore the relationship between character count and byte count, acknowledging that ideographic languages might be more concise on paper but not necessarily in terms of digital storage.
Additionally, we will discuss:
The "Cost of Ideas" for LLMs: We will define the concept of "cost of ideas" in the context of LLMs as the number of tokens required to represent the same idea.
In my previous post, I showed that large language models (LLMs) heavily optimized for English and Latin-based languages exhibit consistently higher token counts when processing non-Latin scripts. This discrepancy in token counts translates to increased computational costs for operating LLM-based applications like ChatGPT on non-Latin languages. Building on this foundation, my focus on this post will be on investigating the "Cost of Ideas" in ideographic and orthographic writing systems. The primary objective is to explore how the fundamental distinctions between these two language categories influence their digital footprint in representing and conveying concepts and ideas.
Ideographic vs. Orthographic Languages
Ideographic languages, are writing systems where each character or symbol represents a complete word or concept. Chinese, which uses thousands of characters (called hanzi) is the most prominent example of this type of writing system.
Key Features of Ideographic Languages:
Characters Represent Ideas: Instead of corresponding to phonetic sounds, each character in an ideographic language symbolizes an entire word or concept. the character 木 in Chinese represents the word "tree" or the concept of "wood."
Extensive Character Set: To encompass a language's full vocabulary, ideographic writing systems require a vast number of characters, often numbering in the thousands or tens of thousands. The Kangxi dictionary, one of the most comprehensive Chinese dictionaries, contains over 47,000 characters.
Context Matters: While some characters may have multiple pronunciations or meanings, the context in which they appear often provides clues to their intended interpretation. The character 行 can mean "to walk" or "behavior," depending on the context.
Character Composition: In some languages (like Chinese), characters can be built from simpler components that offer hints about meaning or pronunciation. The character 林, meaning "forest," is composed of two instances of the character 木 (tree).
In contrast, orthographic languages utilize a set of symbols, typically letters or syllabic characters, to represent the individual sounds (phonemes) that make up spoken words. These symbols are then combined to form words based on their phonetic values. The most familiar example of an orthographic language is English.
Key Features of Orthographic Languages:
Phoneme Representation: The letters or symbols in these writing systems correspond to the smallest units of sound (phonemes) in the spoken language. For example, the letter "c" represents the /k/ sound in the word "cat."
Limited Symbol Set: Compared to ideographic languages, orthographic systems typically require a relatively small number of symbols to function. The English language has 26 alphabets.
Phonetic Combination: Words are formed by combining these symbols based on their phonetic values, creating a more direct link between sound and written word. The word "book" is composed of the letters "b," "o," "o," and "k," representing the sounds /b/, /ʊ/, /k/.
In addition, there are some languages like Japanese that incorporate both ideograms (kanji characters borrowed from Chinese) and phonetic scripts (hiragana and katakana) within their writing system. For example, the Japanese word for "computer" is written as コンピューター (using hiragana and katakana) or 電脳 (using kanji characters).
Universal Declaration Human Rights as a Lens for Comparing "Cost of Ideas"
To analyze the "cost of ideas" across ideographic and orthographic languages, we will leverage the Universal Declaration of Human Rights (UDHR) as a parallel corpus in Nepali (orthographic), English (orthographic), Japanese (hybrid with ideographic kanji and syllabic kana), and Chinese (ideographic).
The UDHR translations are maintained and overseen by the United Nations (UN) ensuring that UDHR's articles are conveyed accurately and with semantic equivalence across all languages. This ensures that any differences observed in the "cost of ideas" are primarily due to the inherent characteristics of the writing systems themselves, rather than discrepancies in translation.
We will examine the parallel translations across these languages to understand how the same ideas when represented using different writing systems vary in terms of the cost that a digital system has to bear.
Preprocessing the Data
This plain text version of UDHR was originally prepared and hosted by the Unicode Consortium under the "UDHR in Unicode" project. While as of January 2024, the Unicode Consortium is no longer hosting the UDHR in Unicode project, the XML files with translations in multiple languages are available at UDHR in XML.
I pre-processed the XML files in Mandarin Chinese (Simplified), Mandarin Chinese (Traditional), English, Japanese, and Nepali languages. The processed dataset includes 31 rows for each language, with a preamble and 30 articles defined in UDHR.
The Trade-Off: Conciseness vs. Digital Footprint
The trade-off between conciseness and digital footprint becomes particularly evident when comparing ideographic writing systems, like Chinese, with orthographic systems, like English or Nepali. Let's delve deeper into this trade-off by examining the grapheme and byte counts for the text in our dataset.

Grapheme Count and Conciseness
Grapheme count refers to the number of characters, such as letters or ideographs, needed to represent a word or concept. Ideographic scripts like Chinese exhibit a significant advantage in conciseness. In our dataset, Traditional Chinese has an average grapheme count of 82.54, and Simplified Chinese has 82.45. In contrast, the average grapheme count for English is considerably higher at 321.70. This conciseness in ideographic scripts stems from their ability to convey complex ideas and concepts through a single ideographic character, reducing the need for multiple graphemes.

Byte Count and Digital Footprint
However, the byte count represents the number of bytes required to encode the text digitally. Despite their lower grapheme counts, Traditional and Simplified Chinese texts required an average of 246.41 and 240.77 bytes, respectively, to encode their characters. This higher byte count is a consequence of the complex character encodings required for ideographic scripts, which often involve multiple bytes per character. The cost of an increased digital footprint.
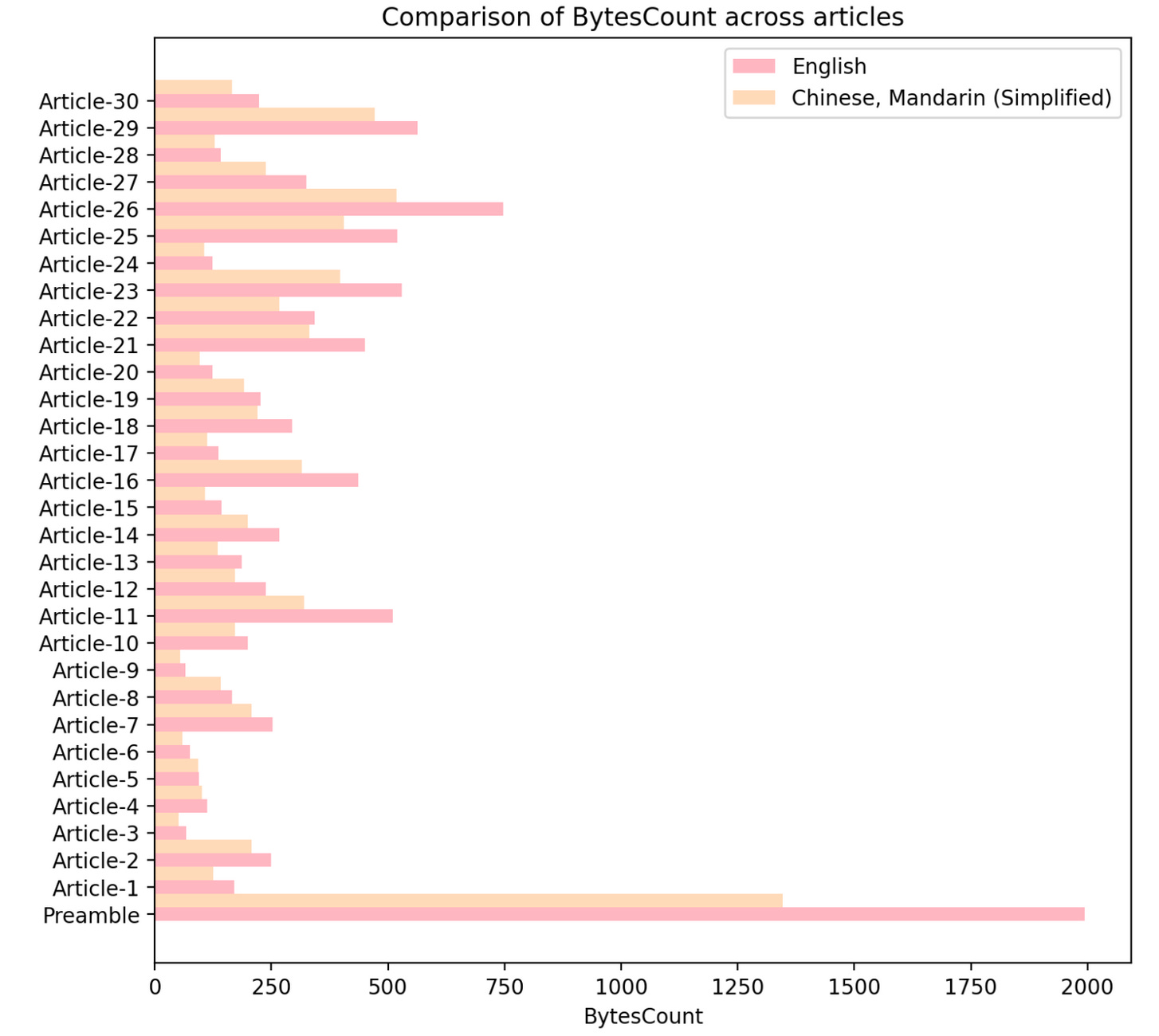
English and the Trade-Off
On average, English requires 3.9 times more graphemes than Traditional and Simplified Chinese to convey the same concepts. However, when it comes to byte counts needed for digital encoding, the gap narrows down drastically. English requires only 1.31 times more bytes than Traditional Chinese, and 1.34 times more bytes than Simplified Chinese. This highlights the trade-off: while Chinese is far more concise requiring fewer graphemes, English benefits from a simpler encoding requiring fewer bytes per grapheme representation compared to the ideographic Chinese scripts.
The Case of Japanese
Similarly, Japanese, which incorporates ideographic kanji characters borrowed from Chinese, and orthographic characters hiragana and katakana, has an average grapheme count of 124.35 in our dataset, lower than English. However, the byte count for Japanese text jumps to 371.83, exceeding even that of English. This significant increase in byte count can, again, be attributed to the complex character encodings for Japanese characters.
In essence, while ideographic scripts like Chinese and Japanese offer conciseness in terms of grapheme counts, they often require more bytes to encode digitally, resulting in a trade-off between conciseness and digital footprint. This trade-off has implications for tasks such as text storage, transmission, and processing within language technologies and applications.
Script Intricacies and Their Impact on Digital Footprint
While ideographic scripts like Chinese exhibit a clear trade-off between conciseness in grapheme counts and an increased digital footprint due to their complex character encodings, the case of Nepali presents a different challenge.
Even though Nepali, like English, is an orthographic language, its text characteristics in our dataset differ significantly in terms of grapheme and byte count. While Nepali uses far fewer graphemes on average (194.80) compared to English (321.70), this efficiency stems from the unique features of the Devanagari script used by Nepali. Unlike the Latin script, where consonants often need additional characters to represent sounds like syllables or consonant clusters, Devanagari generally uses a single character per sound. This is because Devanagari consonants typically come with an inherent vowel sound, a characteristic not always present in the Latin script. This allows Nepali texts to be represented with fewer graphemes on average compared to their English.
However, the byte count tells a different story. Nepali text required a staggering 759.09 bytes on average to encode digitally, over 2.3 times higher than the 321.96 bytes needed for English text. This disproportionately high byte count for Nepali, despite its lower grapheme count compared to English, highlights the complexity involved in digitally encoding the intricate system of consonant clusters, vowel diacritics, and combining characters present in the Devanagari script.
The "Cost of Ideas" for LLMs
As explored in my previous work, the number of tokens required to represent ideas in LLMs can vary significantly across languages. It really depends on how the tokenizer was trained for each model. While the inherent characteristics of a language influence the number of graphemes needed to represent ideas, the tokenization method plays a crucial role in determining the actual token counts within the LLM.If the tokenizer is trained on a diverse dataset that includes a good representation of ideographic languages like Chinese, it can potentially learn to tokenize these languages more efficiently. This can lead to lower token counts and a cost advantage for representing ideas in the LLM.
You can find the visualizer here.



If the tokenizer is trained on a diverse dataset that includes a good representation of ideographic languages like Chinese, it can potentially learn to tokenize these languages more efficiently, resulting in lower token counts and, consequently, a cost advantage for representing ideas within the LLM.
Conversely, a tokenizer trained on data skewed towards certain languages or writing systems may struggle to tokenize other languages optimally. This can result in higher token counts and increased costs for representing ideas in those languages. This seems to be the case with GPT-4 tokenization, where it exhibits sub-optimal performance when tokenizing texts in non-Latin languages.
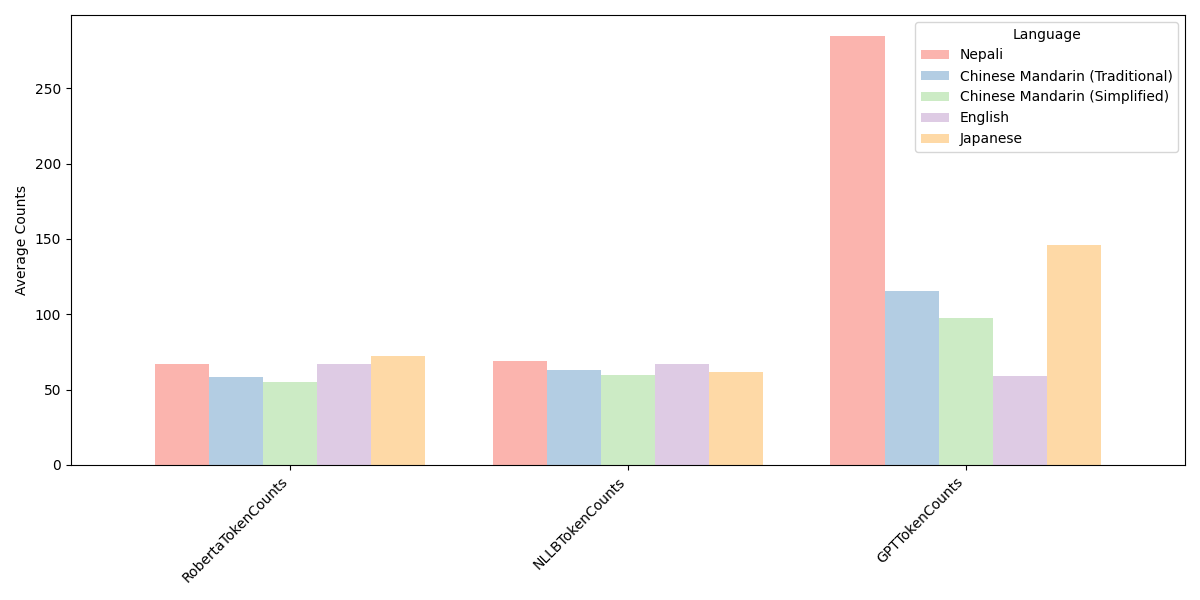
This observation highlights the importance of carefully curating the training dataset, as well as tailoring the tokenization process when developing large language models. By ensuring that the tokenizer is exposed to a diverse range of languages, including ideographic scripts, during the training process, LLMs can potentially leverage the inherent advantages of certain writing systems. For example, they can exploit the compact representation of ideas offered by ideographic languages like Chinese. Ultimately, the tokenization method and the quality of the training data can significantly impact the cost and efficiency of representing ideas across different languages within large language models.
Acknowledgements
Nolan Kramer, for not just asking the question that became the basis of this post but also for the discussions throughout the time I was working on this project.
Gwendolyn Gillingham, for helping me with the study and providing the idea of using the UDHR dataset.
 | A guest post by
|