


Earlier this month, I stumbled upon two articles that discussed the disparities in tokenization among languages titled "All languages are NOT created (tokenized) equal" and “Why is GPT-3 15.77x more expensive for certain languages?”. This piqued my interest and motivated me to conduct further investigations on my own.
In this article, I'll discuss Byte-Pair Encoding (BPE) based tokenization and the disparities in the tokenization process across different languages. Using the Indo-European language family as a case study, I will show how these discrepancies arise not from inherent language family differences but rather from the training data and the representation of characters in Unicode for each language. In addition, I will:
Explore GPT-4 vocab and compare it to XML-RoBERTa and NLLB-200-distilled-600M.
Explore token length distribution for Indo-European languages: English, French, Spanish, Hindi, and Nepali.
Explore the relationship between grapheme counts vs token lenghts across the languages.
Compare the speed of tokenization for the three tokenizers across five languages mentioned above.
How LLMs break down language from text to tokens
Let’s buid GPT tokenizer by Andrej Karpathy was very helpful in understanding the tokenizers used by LLMs.
Tokenization is a fundamental process that involves breaking down a text into smaller units called tokens, typically words or subwords. LLMs like GPT-4 utilizes a technique called byte pair encoding (BPE) for tokenization. It iteratively merges the most frequently occurring pairs of consecutive characters into single units, forming a dynamic vocabulary that adapts to the unique characteristics of the training data. This approach enables LLMs to effectively handle rare words and improves its computational efficiency compared to traditional word-based methods.
In addition, instead of treating text as sequences of individual characters, GPT-4 uses byte-level BPE for tokenization and leverages the properties of UTF-8 encoding, which represents text using sequences of bytes called code points.
Byte-Level BPE in GPT Models
By working with bytes instead of characters, these models achieve the following advantages, in addition to dynamic vocabulary building:
Compact Vocabulary: It starts with a base vocabulary consisting of 256 individual bytes, representing all possible byte values in UTF-8 encoding. This small vocabulary size translates to computational efficiency and faster processing.
Universal Character Representation: This ensures all characters, regardless of their origin, can be represented using a combination of bytes, effectively eliminating the need for "unknown tokens." This allows the models to handle diverse text from various languages and writing systems seamlessly.
Decoding GPT-4 vocab
To understand the discrepancies discussed above, I first looked into the vocab used by GPT-4. Tokens in the original vocab cl100k_base.tiktoken used by the cl100k_base tokenizer, which is the BPE tokenizer used by GPT-4 and is encoded in base64. I converted vocabulary to UTF-8 for my analysis. Some tokens resulted in encoding errors due to incomplete generation, highlighting limitations of byte-level BPE in handling uncommon texts and text in writing systems other than latin.
The decoded vocabulary comprises 70,988 entries containing only Latin characters. This suggests a potential bias towards Latin-based languages in GPT-4's training data.
There are 29,268 entries containing at least one non-Latin character. This indicates that the model was exposed to other languages during training.
Among these non-Latin entries, 803 entries partial byte sequences.

Limitations in representing uncommon texts and other writing systems
While byte-level BPE effectively eliminates the need for unknown tokens with a compact vocabulary, there are some limitations, especially in representing uncommon texts and texts in writing systems other than latin.
Despite universal character representation, it might struggle with tokenizing uncommon texts not seen during training. For cases involving extremely rare combinations or characters from under-represented writing systems BPE might resort to suboptimal tokenization, like breaking down the sequence into individual bytes, which can impact accuracy.
English letters are assigned a one-byte encoding in UTF-8. However, this is not true for all languages, some languages use multiple bytes. Hindi and Nepali are examples of such languages. Both Hindi and Nepali use Devanagari script which has a larger character set than the basic Latin alphabet used in English. This means that these languages need more unique symbols to represent its characters. UTF-8 encodes characters using a variable number of bytes depending on their rarity. To represent these less common characters, UTF-8 uses two, three, or even four bytes. Since a byte-level BPE model would treat each byte as a separate token, a letter in languages like Hindi or Nepali would be broken down into multiple tokens, potentially impacting the model's understanding and generation capabilities. The impact of the process in model’s understanding in out of the scope of this article.
Let's explore how the byte-based BPE tokenization process can lead to this issue i discussed with the Nepali word "सोमबार" (sombaar, meaning "Monday") as an example.
Unicode Code Points: The word "सोमबार" is represented by the following Unicode code points in hexadecimal:
स: 0x0938 ो: 0x094B म: 0x092E ब: 0x092C ा: 0x093E र: 0x0930UTF-8 Encoding: When encoded using UTF-8, the word "सोमबार" becomes the following byte sequence:
स: 0xE0 0xA4 0xB8 ो: 0xE0 0xA5 0x8B म: 0xE0 0xA4 0xAE ब: 0xE0 0xA4 0xAC ा: 0xE0 0xA4 0xBE र: 0xE0 0xA4 0xB0
Byte-based BPE Tokenization: During the training BPE can , for example for character
ब, merge the byte sequences0xE0 0xA4 into one single token and leaves out 0xAC as a separate token depending on the data it has seen.This causes the vocab to have byte sequences that do not make up a valid code point. So let’s assume after several iteration we have the following vocabulary.0xE0 0xA4 0xB8 0xE0 0xA5 0x8B 0xE0 0xA4 0xAE 0xE0 0xA4 --> incomplete 0xAC --> incomplete 0xE0 0xA4 0xBE 0xE0 0xA4 0xB0Tokenization of "सोमबार": When the tokenizer tries to tokenize the word "सोमबार", it would then generate the following sequence of tokens:
['0xE0 0xA4 0xB8', '0xE0 0xA5 0x8B', '0xE0 0xA4 0xAE', '0xE0 0xA4', '0xAC', '0xE0 0xA4 0xBE', '0xE0 0xA4 0xB0'] Decoding at token id level: ['स', 'ो', 'म', '�', '�', 'ा', 'र']
When decoding the tokens individually, you would encounter an unicode decoding error and by default one would encounter an Unicode replacement character (�). See more on this here.Note: A slightly different case would be where byte sequences for multiple characters would be combined by BPE to one entry in vocab, which would also cause similar issue.
Decoding at token level: ['स', 'ो', 'म', '�', '�', 'ा', 'र'] Decoding at input level: सोमबारHowever, when you decode the entire sequence of tokens together, the tokenizer can correctly reconstruct the original word "सोमबार" by combining the individual byte sequences represented by each token.

Factors influencing high invalid byte sequences in vocab
The quality and size of the training data in a particular language can expose algorithm to learn sub-optimal vocabulary. Languages with less diverse or smaller training datasets may exhibit higher rates of invalid byte sequences due to insufficient coverage of character combinations or linguistic phenomena.

In addition to the quality and size of training data, some of the factors that influence high invalid byte sequences in vocab are:
Script Complexity: Languages with more complex scripts, such as those with non-Latin scripts like Devanagari, Thai, or Chinese characters, may have a higher likelihood of invalid byte sequences representation in vocab. These scripts often have a larger number of characters and more complex character compositions, leading to a wider range of possible byte sequences and potential challenges in tokenization.
Character Frequency: Characters that are less frequent in the training data may have their byte sequences split more frequently during merging, increasing the likelihood of incomplete tokens.
Word Morphology: Languages with rich morphology, such as agglutinative languages, may exhibit a larger number of morphemes or affixes, leading to more opportunities for byte sequences to be split during tokenization.
Can training with more multi-lingual data solve this?
Looking at the vocab we can infer that GPT-4 was heavily optimized towards English. In this section, I will compare the GPT-4 tokenizer with two other byte-based BPE tokenizers: XML-RoBERTa and NLLB-200-distilled-600M that were trained with multi-lingual data. The purpose of this study is to see if and how exposing more multi-lingual data in training affects tokenization. I chose these two tokenizers in particular because in Denys Linkov’s blog he shows that the ratio between the largest and smallest token numbers is the lowest for these two tokenizers in comparison to the others he compared.
A more diverse and distributed vocabulary
NLLB and XML-RoBERTa demonstrate significantly more diverse vocabularies compared to GPT-4’s cl100k_base vocab:
Non-Latin characters: NLLB and XML-RoBERTa contain roughly 79.53% and 83.62% non-Latin entries respectively, while cl100k_base only has 29.2%. This indicates that NLLB and XML-RoBERTa can handle a wider range of languages beyond Latin-based ones.
Vocabulary size: NLLB and XML-RoBERTa have a much larger vocabulary size, with 2.55 and 2.49 times more entries than cl100k_base with a more distributed sub-tokens across languages.

I also found that cl100k_base vocab contains a significantly higher number of entries representing incomplete byte sequences, at roughly 29.7 times and 25.1 times more than NLLB and XML-RoBERTa respectively. The limited exposure to non-Latin byte sequences during training might explain large number of incomplete sequences in cl100k_base vocab. As mentioned earlier section, a smaller or less diverse multilingual corpus could restrict the model's ability to learn the proper representation of uncommon text sequences.
Aya Dataset
For this study, I used Aya Dataset, which contains human-curated prompt-completion pairs in 65 languages written by fluent speakers of the languages. I chose this dataset for three reasons, 1. diverse sequences in terms of lengths and topic, 2. contains all languages of interest, and 3. since it is human-curated, the dataset is of high quality, which is what I observed for English, Nepali, and Hindi.
I took texts in inputs column of the dataset and kept a max of 1500 samples for each languages. The total samples in the final split for the five languages of interest are:
English - 1499
French - 1349
Spanish - 1500
Hindi - 1087
Nepali - 1500
Results
Tokenization Trends Across Languages
Although, I used a different dataset, I observed a similar trend in token length distribution as discussed in the articles: "All languages are NOT created (tokenized) equal" and “Why is GPT-3 15.77x more expensive for certain languages?”.
Inspired by the first work, I have created a similar dashboard for this work.
The distribution of token lengths across languages non-English languages (French, Spanish, Hindi, and Nepali) were closer to English for NLLB and XML-RoBERTa tokenizers in comparison to GPT-4 tokenizer. However, for GPT-4 tokenizer, the token distribution for non-latin languages (Hindi, and Nepali) were very different from that of English, with non-latin languages (Hindi, and Nepali) having a consistently higher number of tokens across the samples.

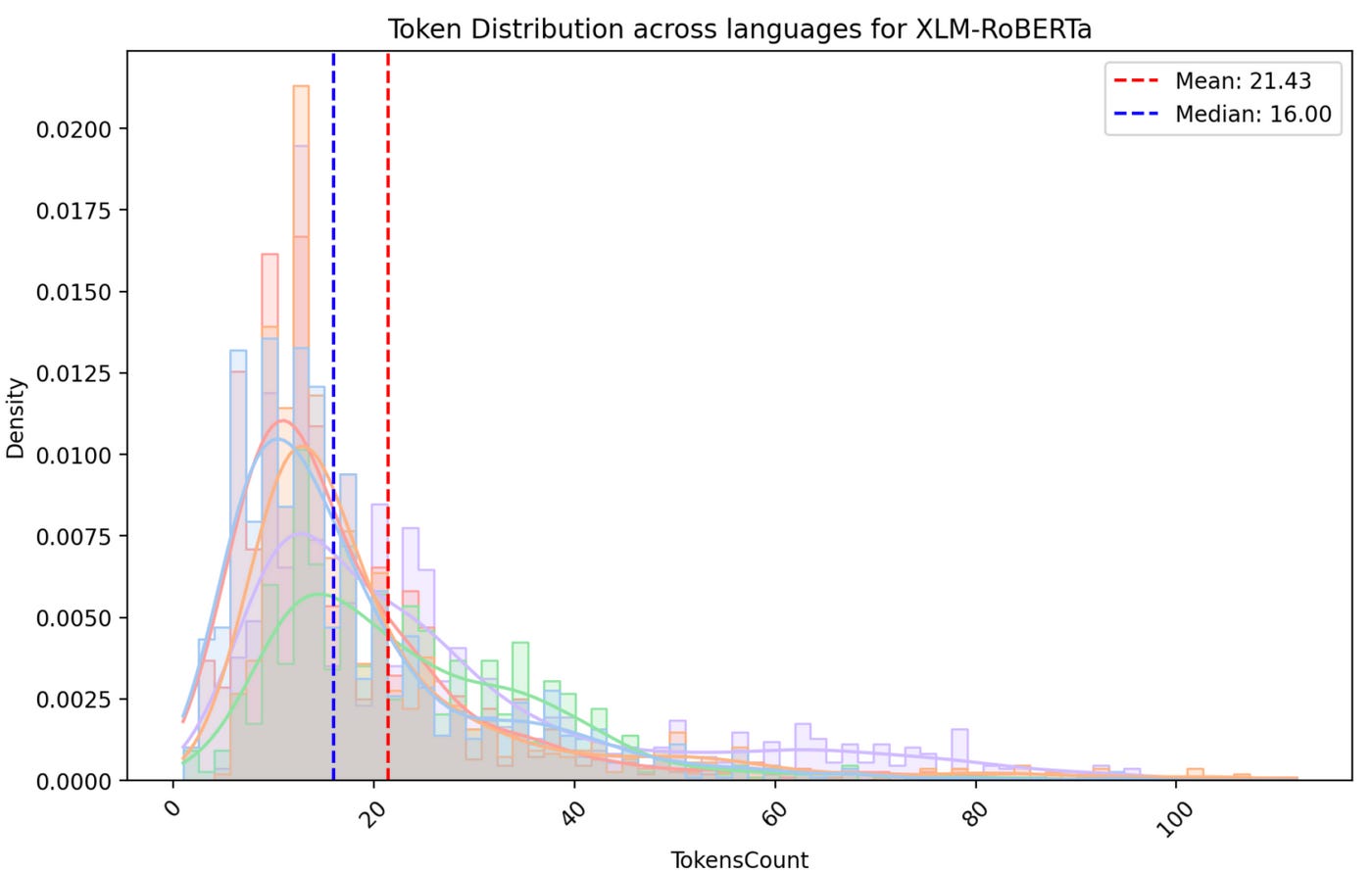
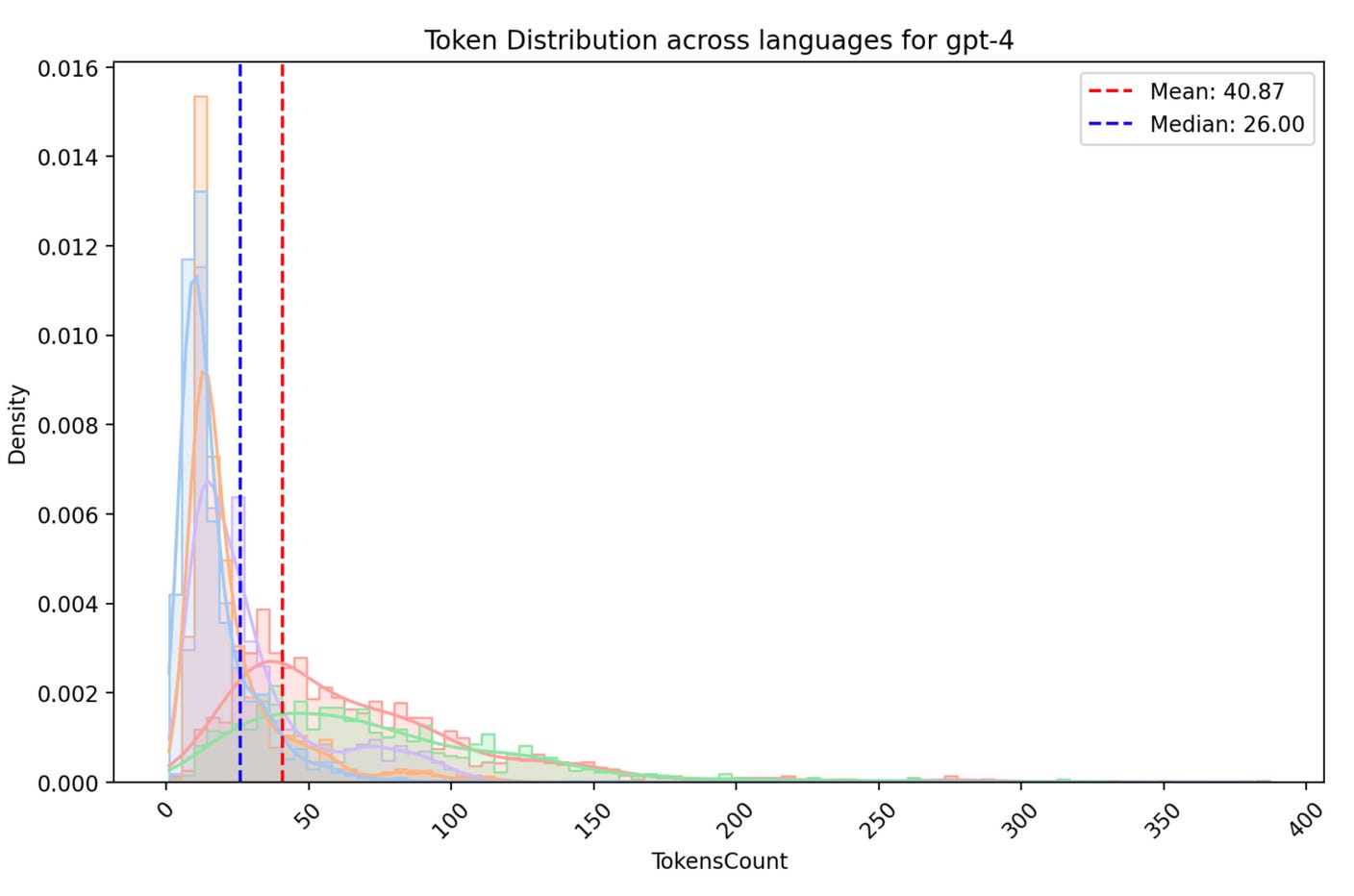
The median token length for non-Latin languages (Hindi and Nepali) is only slightly higher than for Latin languages (English, French, Spanish), 17 vs. 16, for NLLB and RoBERTa tokenizers. However, GPT-4 tokenizer exhibits a significantly larger difference with median token lenghts of 62 for Hindi and Nepali vs. 16 for English, French, and Spanish.
This observation suggests that training on a more comprehensive multilingual corpus can influence token length distribution. NLLB and RoBERTa, likely trained on broader datasets, show a smaller difference in token lengths between Latin and non-Latin languages compared to GPT-4 tokenizer, which might have been trained on a less diverse corpus.
There was no replacement token for any sample in the dataset for NLLB and XML-RoBERTa, while there were a fair amount on replacement tokens, for non-latin languages for GPT-4 tokenizer.

Graphemes vs Token Counts
I compared the grapheme count (number of written characters) to the token count (number of tokens after tokenization) for the above tokenizers and observed that GPT-4’s tokenizer stands out with a much higher token count compared to its grapheme count for Hindi and Nepali.
While all three models utilize BPE (Byte Pair Encoding), NLLB and RoBERTa tokenizers, likely trained on broader multilingual datasets, would have encountered various writing systems and grammatical structures. This exposure allows them to adapt their tokenization strategies to handle the complexities of non-Latin languages.
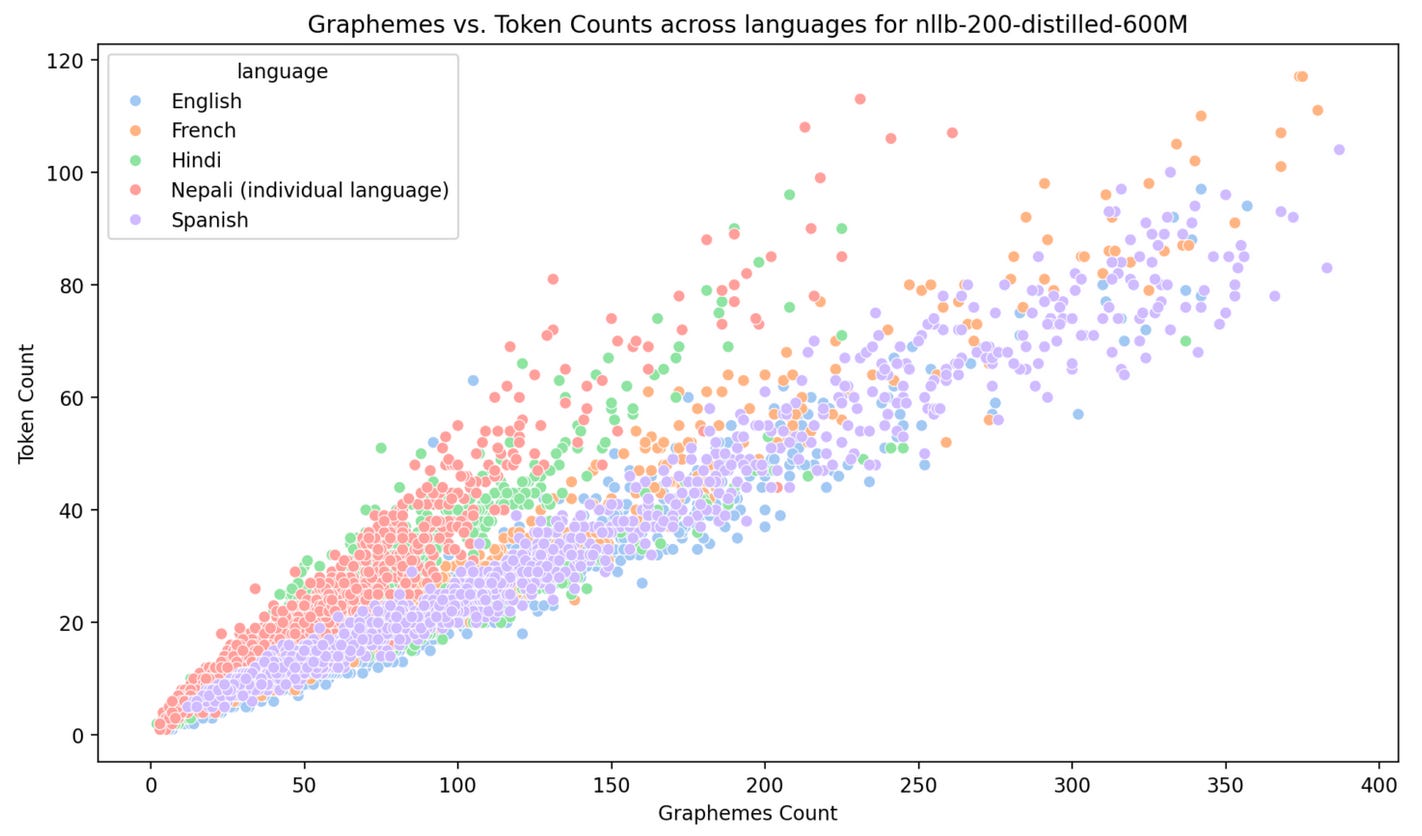

GPT-4 tokenizer seems to have been heavily optimized for English and might not have been adequately exposed to the specific characteristics of non-Latin languages. As a way to manage unseen characters or complex word structures, GPT-4 tokenizer seems to be excessively splititting words into subwords such that a lot of the subwords are incomplete/sub byte sequences, inflating the token count compared to graphemes.
Nepali and Hindi both have a complex morphology involving prefixes, suffixes, and other meaningful units and limited exposure to such structures during training could hinder GPT-4 tokenizer’s ability to effectively tokenize these languages.

Does this affect the overall tokenization time?
The peak distribution of time taken for tokenization by NLLB and RoBERTa is around 2.2 seconds and 2.0 seconds, respectively. cl100k_base is significantly faster in comparison with peak distribution of time at 0.0006 seconds. However, the speed of tokenization only varies slightly for a tokenizer across the languages.


This metric was collected from a device with following configuration:
Courtesy: Infinity Technology Inc.
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 48
On-line CPU(s) list: 0-47
Vendor ID: GenuineIntel
Model name: Intel(R) Xeon(R) CPU E5-2690 v3 @ 2.60GHz
CPU family: 6
Model: 63
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 2
Stepping: 2
CPU max MHz: 3500.0000
CPU min MHz: 1200.0000
Caches (sum of all):
L1d: 768 KiB (24 instances)
L1i: 768 KiB (24 instances)
L2: 6 MiB (24 instances)
L3: 60 MiB (2 instances)
NLLB and RoBERTa both have a larger vocabulary, so it natural that these take more time to map the input text to corresponding tokens. However, the relationship between the speed of tokenization and vocabulary size is not linear.
Conclusion
To conclude, in this article I explored the impact of training data and character representation on tokenization discrepancies for byte-based BPE tokenizers across languages. While focusing on the Indo-European language family, the findings suggest that these disparities primarily stem from the models' exposure during training and how characters are represented in unicode.
Key observations:
GPT-4 vocabulary differed significantly from NLLB-200-distilled-600M and XML-RoBERTa, both in terms of size and distribution on non-latin tokens.
Token length distribution varied across languages, for all the tokenizers. While the variation is not significant for NLLB-200-distilled-600M and XML-RoBERTa, the token counts for non-latin languages are much higher for GPT-4 tokenizer.
GPT-4 tokenizer showed a large discrepancy between grapheme count and token length for non-latin languages.
Tokenization speed varied only slightly across the languages for each tokenizer but GPT-4 tokenizer was atleast twice as fast compared to NLLB-200-distilled-600M and XML-RoBERTa tokenizers.
Future considerations:
Investigating the tokenization strategies employed by each model in more detail.
Exploring the performance of these models on downstream tasks involving non-Latin languages would be valuable.
Explore if a high token count in GPT-4 translates to poor generation and language understanding capbilities.
Hi, thanks for this very comprehensive write-up. Some really interesting insights. I just wish there were more citations. One I'm looking for in particular is about the claim that sub-optimal tokenization impacts accuracy. Do you have a reference for this? Or are you working on this, because evaluating the correlation between model performance and tokenization (for Nepali, for example) sounds like something worth exploring.