

Strawberry (o1) - Does changing language affect its reasoning?
What is going on inside OpenAI's o1 model and if changing language affect its reasoning - a short bilingual experiment.

On September 12, OpenAI released its new series of AI models trained with reinforcement learning to perform complex reasoning - called o1. Two versions of the model were released, o1-preview and o1-mini. These models are trained to “think” before answering or it is trained to generate a long chain of thought (CoT) before answering. This allows the model to handle complex reasoning and solve tasks that require reasoning. With o1, we will see a shift in focus from scaling pretraining to inference compute.
“o1 marks the start of a new era in AI, where models are trained to "think" before answering through a private chain of thought. The more time they take to think, the better they handle complex reasoning. We're no longer limited by pretraining paradigm; now, we can scale through inference compute, opening up new possibilities for capabilities and alignment.
- Part of a tweet by Mira Murati, CTO, OpenAI on Twitter
There are many speculations on the o1 series of models and how the models were potentially trained to think, although the specific techniques used by OpenAI is still not public. In this post, we will first summarize what we know from official sources - release note and AMA by OpenAI o1 team on Twitter. We will also look into the “Let’s Verify Step by Step”, which was published last year and many, including me, believe that this paper could provide insights into the techniques used in training the o1 family of models. Finally, I will share my experience with using the o1-mini model for Mathematics and Science questions from SEE exams in Nepal. I will also ask the same set of questions in Nepali and English to understand if changing language affects the model’s reasoning.
Before we jump into the rest of the blog - I highly recommend reading the following:
Learning to Reason with LLMs, September 12, 2024 by OpenAI
OpenAI o1-mini, Advancing cost-efficient reasoning, September 12, 2024 by OpenAI
Let’s Verify Step by Step, 31 May 2023 by OpenAI
Reverse engineering OpenAI’s o1, September 16, 2024 by Nathan Lambert
Straight From The Source
The o1 series models are trained with reinforcement learning to think before they answer, which allows for the model to perform sophisticated reasoning. They produce an internal chain of thought before responding, which allows these models to provide highly accurate results - especially for domains like science, mathematics, programming and analytics that require structured thinking and step-by-step problem solving.
“o1 ranks in the 89th percentile on competitive programming questions (Codeforces), places among the top 500 students in the US in a qualifier for the USA Math Olympiad (AIME), and exceeds human PhD-level accuracy on a benchmark of physics, biology, and chemistry problems (GPQA).
- Learning to Reason with LLMs, September 12, 2024 by OpenAI
The o1 family of models are trained with reinforcement learning, where the models are likely trained using large datasets annotated for correctness at every step of its reasoning process. This allows that the model to learn to reason before returning the answer. In their research, they found that the performance of the model consistently improved with more reinforcement learning (train-time compute) and with more time spent thinking (test-time compute).
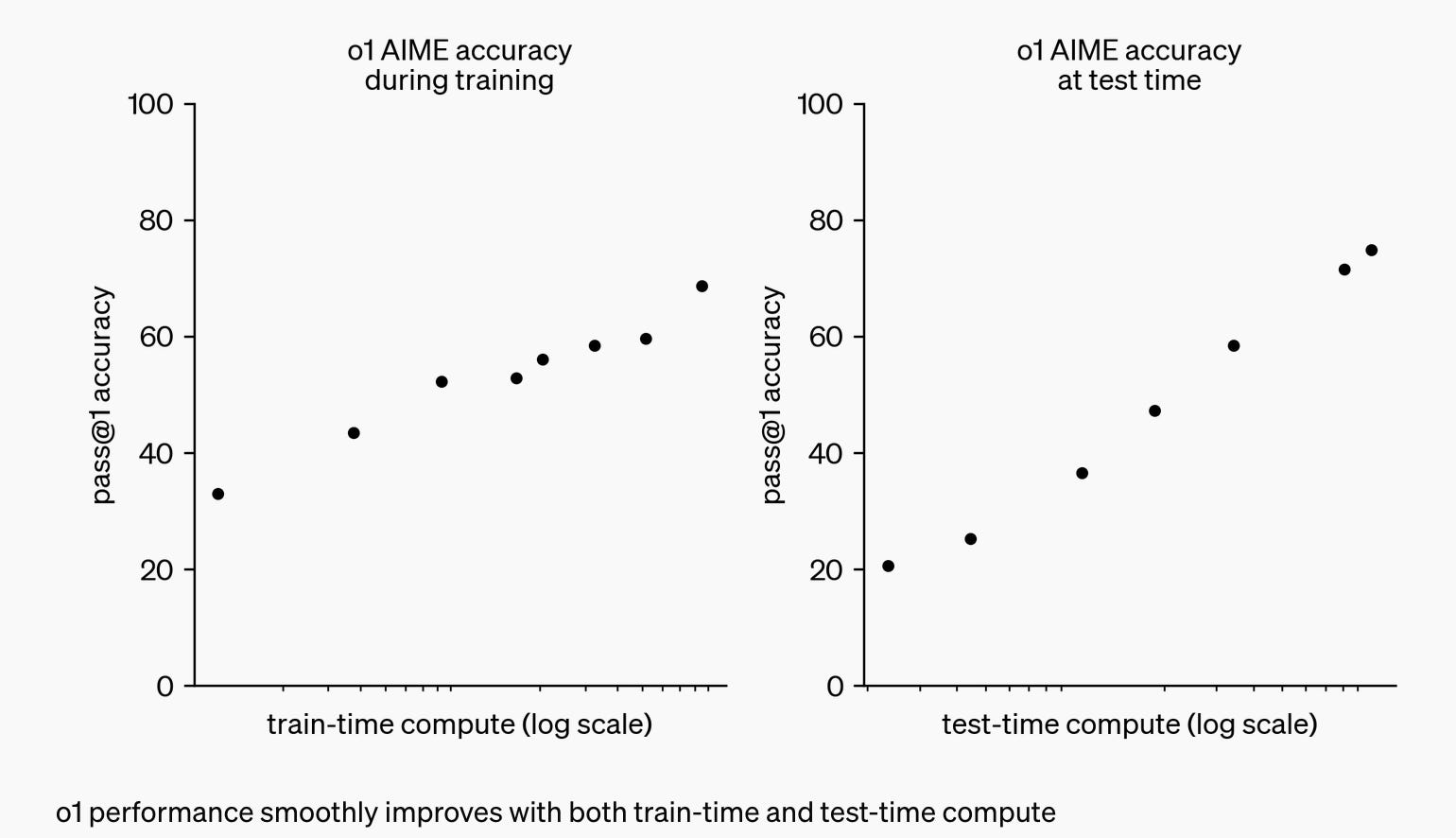
On contrary to the most of existing LLMs where a very little amount of compute is dedicated to inference, o1 spends more time on inference. o1 model is a paradigm shift in how compute resources are allocated in LLMs. As Jim Fan pointed out in his Twitter post - now we see a paradigm of inference-time scaling deployed in production.

In a League of Its Own
The evaluation results shared in the blog shows that o1 has superior reasoning in comparison to GPT-4o. It significantly outperforms GPT-4o in 54 out of 57 MMLU subcategories. According to OpenAI - “o1 models offer significant advancements in reasoning, but they are not intended to replace GPT-4o in all use-cases.”


The results are impressive, although the training process of the model remains undisclosed - there are speculations, nevertheless. In the next section, we will briefly discuss “Let’s Verify Step by Step”, which could potentially give away the techniques used in training the o1 family of models.
Let’s Verify Step by Step
Let’s Verify Step by Step, looks into methods to train reliable reward models that can detect hallucinations for LLMs. In this work, the researchers investigate two methods for training reward models: outcome supervision and process supervision.

Outcome supervision reward model provides feedback for a final result from LLMs. The LLM tries different CoT paths and receives feedback based on the final outcome. The correct responses get rewarded while the incorrect ones get penalized and over time the model learns to discard paths that are unsuccessful and reinforce the ones that are successful.
Process supervision on the other hand provides feedback for each intermediate reasoning step, not just the final state. This trains the model to break down the problems into logical steps - similar to what a human would. This would allow the model to not just be structured and logical it would also be able to identify mistakes when they occur during a reasoning step.

So we know that o1 thinks before responding and this thinking process involves reinforcement learning to train the model to generate a private chain of thought (CoT). Based on this, it is fair to speculate that the o1 model likely iterates through and evaluates each action state in its CoT, which allows the model to reason and generate the best CoT path that leads to a correct solution. There is a possibility that OpenAI could have used either of the methods or a combination of both outcome and process supervision. I am leaning towards the latter because in their investigation in Let’s Verify Step by Step they found that models trained with process supervision significantly outperformed those trained with outcome supervision on challenging reasoning tasks.
However, with process supervision reward model alone, the model might keep generating paths that don’t lead to an answer - so an outcome supervision reward model might have been used in combination as well to give feedback on whether the LLMs got the answer right or some kind of stopping criterion could have been used. By combining these two models, the system gets feedback on each state and the final answer - this helps the model to correct its path if it gets any of the intermediary paths wrong. Additionally, Q* framework could be employed during CoT generation to help the model choose the next best reasoning state, making the overall process more efficient and strategic.
o1 Inference
While o1 outperforms the existing models several on benchmarks, it is still an extremely expensive model in comparison. o1-preview available via chat completion endpoint and costs $15 per 1 million input tokens and $60 per 1 million output tokens, which is much higher than GPT-4o that costs $5 per 1 million input tokens and $15 per 1 million output tokens.
Access. As of now there are two reasoning models available in beta versions: o1-preview and o1-mini with limited features. The preview model is only an early checkpoint of the o1 model. Many chat completion API parameters are not available yet. Additionally, if you want to access o1 models via chat completion API you need to be a Tier 5 user.
o1-preview: o1 model, designed to reason about hard problems using broad general knowledge about the world; Limit: 30 messages a week.o1-mini: a faster and cheaper version of o1, particularly adept at coding, math, and science tasks where extensive general knowledge isn't required; Limit: 50 messages a week.
Scaling o1 for general use-case and a widespread deployment is hard, which is very likely the reason for limited access. The o1 model is also a lot more expensive than GPT-4o. The users are also charged for the reasoning tokens, which they don’t have access to. While the improvements are great - the inaccessibility - not so much.
- “While reasoning tokens are not visible via the API, they still occupy space in the model's context window and are billed as output tokens.
- Reasoning models by OpenAI
We know that o1 is 6x more expensive than GPT-4o but offers advanced reasoning capabilities. While tokenization and pricing have improved for GPT-4o, especially with recent tokenizer updates, tokenization in diverse, non-Latin languages like Nepali remains suboptimal and more expensive. So now, let's test if o1 is worth the extra cost for a non-Latin language like Nepali. Also, if changing language affects o1’s reasoning ability?
A Short Bilingual Experiment
In this brief experiment, I will present GPT-4o and o1-preview with 10 SEE examination questions via the chat application - consisting of 5 questions in science and 5 in mathematics. Each question is in Nepali and English. This will help us explore o1’s reasoning abilities and assess how it handles questions in a non-Latin low-resource language compared to English.
Note: I am OpenAI-poor, so these examples were run through the regular chatGPT with GPT-4o and o1-preview and not via the API and the total output tokens are the tokens generated via tiktoken for comparison, so this is just an estimated difference and not an actual one.
Correctness. Out of the 5 general science questions in English and Nepali, both GPT-4o and o1-preview got all 5 questions right. For 5 mathematics questions both the models got one question wrong each, different questions. Upon inspection, I found that the cause of mistake in o1-preview was not because of the reasoning or any steps in problem solving but because of a translation error that propagated to the error in the final answer. However, the error with GPT-4o was actually due to a failure in understanding a parameter in the question.

For Example:
एउटा बेलनाको अर्घव्यास 35 से.मि. र अर्धव्यास र उचाइको योगफल 65 से.मि. भए सो बेलनाको वक्रसतहको क्षेत्रफल पत्ता लगाउनुहोस् ।
The question translates to: The radius of a cylinder is 35 cm, and the sum of its radius and height is 65 cm. Find the curved surface area of the cylinder.
However when asked this to o1-preview, अर्घव्यास was translated to diameter instead of radius. Also, looking at the following block from reasoning section (refer above image to see the reasoning summary):
Revisiting the measure
I’m clarifying the terminology in Nepali, noting that "अर्थव्यास" means diameter and "अर्धव्यास" means radius, likely a typo. The diameter is 35 cm, and the sum of the radius and height is 65 cm.
अर्धव्यास was was somehow mapped to अर्थव्यास, which was then translated to diameter - which anyway is incorrect. Since, we don’t see the full reasoning stack - it is hard to say what happened here. My guess is अर्धव्यास could have been tokenized incorrectly by the model, which may have confused the model when interpreting the word.
Output token and word count. For both Nepali and English variants of the questions, o1-preview generated significantly more output tokens and words compared to GPT-4o. In English, o1-preview generated 4.5 times more tokens (711.9 vs 158.9) and 3 times more words (344.3 vs 112.9) than GPT-4o. Although less pronounced, a similar trend was observed in Nepali, where o1-preview produced 1.8 times more tokens (495.2 vs 270.4) and 1.6 times more words (150.7 vs 91.4) than GPT-4o. This shows that o1-preview has a tendency to return detailed responses, which is inline with what I observed during my manual analysis of the output. My observation Note: These numbers exclude the thinking tokens that are visible to users. Including these tokens would further increase the counts for o1-preview. Given that the actual reasoning tokens exceed what is shown to users, the true difference in token count - and hence, the cost of solving the same problem - is substantially higher for o1-preview compared to GPT-4o.
Thinking or reasoning token and word count. With o1-preview you get “a summary” of the model’s reasoning process. We know that the actual reasoning tokens are hidden from the users so this looks like a summarized version of the model's reasoning stack.
Interestingly, despite the output token and word counts being significantly higher for English compared to Nepali, the reasoning token and word counts are only slightly higher for English. This suggests that while the model engages in more extensive reasoning and elaboration when generating English responses, the underlying reasoning steps might be more consistent across both languages. One thing that I did notice during my qualitative analysis was that queries in Nepali were often translated to English, which means even when the query is in Nepali the model reasoning happens in English. As a result, while the model can still handle Nepali input, it is likely to lose some of the original context during translation that leads to errors or less precise responses. This probably happens with GPT-4o as well.

Reasoning time. Given how the reasoning unfolds in English regardless of the language of the original query - the reasoning time is similar 8.9 seconds for Nepali v/s 8.6 seconds for English.
Conclusion
The o1 family of models are a new class of models that are trained with the ability to reason. While there is little to no information on how the model was trained - adding up the recent publications, theories of LLMs and information released on the model’s release notes there are speculations that point to how the o1 models were potentially trained. The models could have been trained using either process supervision and outcome supervision reward models or a combination of both. A short bilingual experimentation with 5 science and 5 mathematics questions in Nepali and English shows that the models, both GPT-4o and o1-preview, generate a more verbose response for English. This shows that the models are better at explaining output and generating response in English than in Nepali. However, most of the reasoning happens in English - regardless of the language of the query, so an error in translation in the beginning can cause the entire reasoning chain to be futile. Also, for this use-case I tested the model in GPT-4o was almost as good as o1-preview, however this is a very small experiment and the questions are on the simpler side. It would be fun to test this on more challenging Nepali questions.